
Distributed Systems Lecture and Book Notes
Chapter 1 Introduction
Two development cause the rise of distributed systems:
-
Development of powerful microprocessors. Initially, these were 8-bit machines, but soon 16-, 32-, and 64-bit CPUs became common. Then, multicore CPUs.
-
Invention of high-speed computer networks.
Local-area networks (LAN): Machines within a building to be connected.
Wide-area networks (WAN): Hundreds of millions of machines all over the earth to be connected at speeds varying from tens of thousands to hundreds of millions bps.
1.1 What is a distributed system?
A distributed system is a collection of autonomous computing elements that appears to its users as a single coherent system.
Two characteristics of DS:
-
A collection of computing elements (node) each being able to behave independently of each other.
Group membership
Open group: Any node is allowed to join the distributed system, effectively meaning that it can send messages to any other node in the system.
Closed group: Only the members of that group can communicate with each other and a separate mechanism is needed to let a node join or leave the group
Practice shows that a distributed system is often organized as an overlay network (Örtü, yerleşim ağı in Turkish)
Structured overlay: In this case, each node has a well-defined set of neighbors with whom it can communicate. For example, the nodes are organized in a tree or logical ring.
Unstructured overlay: In these overlays, each node has a number of references to randomly selected other nodes.
Overlay networks are always connected. They form peer-to-peer (P2P) networks
-
Users believe they are dealing with a single system.
User would not be able to tell exactly on which computer a process is currently executing, or even perhaps that part of a task has been spawned off to another process executing somewhere else. Likewise, where data is stored should be of no concern, and neither should it matter that the system may be replicating data to enhance performance. This so called distribution transparency
Middleware and distributed systems
Middleware: DS are often organized to have a separate layer of software that is logically placed on top of the respective operating systems of the computers that are part of the system.
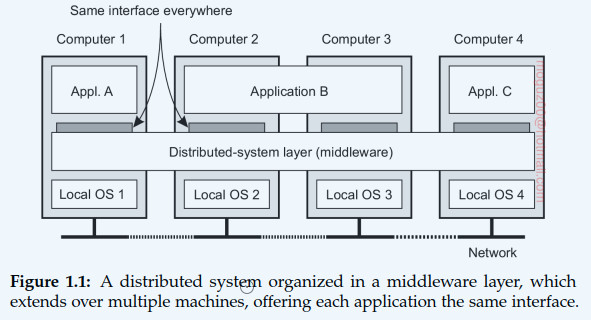
In a sense, middleware is the same to a distributed system as what an operating system is to a computer: a manager of resources offering its applications to efficiently share and deploy those resources across a network. Next to resource management, it offers services that can also be found in most operating systems, including:
• Facilities for interapplication communication.
• Security services.
• Accounting services.
• Masking of and recovery from failures.
Typical middleware services
Communication: Remote Procedure Call (RPC). allows an application to invoke a function that is implemented and executed on a remote computer as if it was locally available.
Transactions: Executing services in an all-or-nothing fashion, referred to as an atomic transaction, the middleware makes sure that every service is invoked, or none at all.
Service composition: It is becoming increasingly common to develop new applications by taking existing programs and gluing them together. This is notably the case for many Web-based applications, in particular those known as Web services. Web-based middleware can help by standardizing the way Web services are accessed and providing the means to generate their functions in a specific order. A simple example of how service composition is deployed is formed by mashups: Web pages that combine and aggregate data from different sources. Well-known mashups are those based on Google maps in which maps are enhanced with extra information such as trip planners or real-time weather forecasts.
Reliability: The Horus toolkit allows a developer to build an application as a group of processes such that any message sent by one process is guaranteed to be received by all or no other process. As it turns out, such guarantees can greatly simplify developing distributed applications and are typically implemented as part of the middleware.
1.2 Design goals
Goals of DS:
- Supporting resource sharing
- Making distribution transparent
- Being open
- Being scalable
Supporting resource sharing
Resources can be virtually anything, peripherals (çevre birimler), storage facilities, data, files, services, and networks. Making distribution transparent is one aim of DS.
Making distribution transparent
Types of distribution transparency
| Transparency | Description |
| Access | Hide differences in data representation and how an object is accessed |
| Location | Hide where an object is located |
| Relocation | Hide that an object may be moved to another location while in use |
| Migration | Hide that an object may move to another location |
| Replication | Hide that an object is replicated |
| Concurrency | Hide that an object may be shared by several independent users |
| Failure | Hide the failure and recovery of an object |
Access transparency
Hiding differences in data representation and the way that objects can be accessed. Different OS and naming conventions, file operations or low-level communication with other processes must be hidden from user and apps.
Location transparency
Users cannot tell where an object is physically located in the system. Achieved by assigning only logical names to resources, that is, names in which the location of a resource is not secretly encoded. Uniform resource locator (URL) http://www.prenhall.com/index.html, which gives no clue about the actual location of Prentice Hall’s main Web server.
Relocation transparency
If the entire site may have been moved from one data center to another, users should not notice. This is becoming increasingly important in the context of cloud computing.
Migration transparency
Supports the mobility of processes and resources initiated by users, without affecting ongoing communication and operations. Communication between mobile phones, regardless whether two people are actually moving, mobile phones will allow them to continue their conversation. Online tracking and tracing of goods as they are being transported from one place to another, and teleconferencing (partly) using devices that are equipped with mobile Internet.
Replication transparency
Resources may be replicated to increase availability or to improve performance by placing a copy close to the place where it is accessed. Hiding the fact that several copies of a resource exist, or that several processes are operating in some form of lockstep mode so that one can take over when another fails. All replicas have the same name. A system that supports replication transparency should generally support location transparency as well.
Concurrency transparency
Two independent users may each have stored their files on the same file server or may be accessing the same tables in a shared database and each user does not notice that the other is making use of the same resource.
Failure transparency
A user or application does not notice that some piece of the system fails to work properly, and that the system subsequently (and automatically) recovers from that failure.
Being Open
A system that offers components that can easily be used by, or integrated into other systems. At the same time, an open distributed system itself will often consist of components that originate from elsewhere.
Interoperability, composability, and extensibility
Define services through interfaces using an Interface Definition Language (IDL)
Interoperability characterizes the extent by which two implementations of systems or components from different manufacturers can co-exist and work together by merely relying on each other’s services as specified by a common standard
Portability characterizes to what extent an application developed for a distributed system A can be executed, without modification, on a different distributed system B that implements the same interfaces as A.
Extensible easy to add new components or replace existing ones without affecting those components that stay in place. An open distributed system should also be extensible. Easy to add parts that run on a different operating system, or even to replace an entire file system
Separating policy from mechanism
System be organized as a collection of relatively small and easily replaceable or adaptable components. Monolithic approach, the older way of development does not provide this.
Caching in Web browsers
Need to consider, Storage, Exemption, Sharing and Refreshing topics. Need to offer a rich set of parameters that the user can set (dynamically).
Trade-off: Strict separation of policies and mechanisms may lead to highly complex configuration problems. To solve this, provide reasonable defaults. Self-configurable systems.
Being scalable
Size scalability: Easily add more users and resources to the system without any noticeable loss of performance.
- The computational capacity, limited by the CPUs
- The storage capacity, including the I/O transfer rate
- The network between the user and the centralized service
Size scalability problems for centralized services can be formally analyzed using queuing theory
λ requests per second processing capacity of the service is µ requests per second fraction
Average throughput X is equal to λ
Utilization U of a service as the fraction of time that it is busy
Response time R: how long does it take before the service to process a request, including the time spent in the queue
R = 1 / (1 - U)
Geographical scalability: Users and resources may lie far apart, but the fact that communication delays may be significant is hardly noticed.
Problems of Geographical scalability
-
Local-area networks based on Synchronous communication In this form of communication, a party requesting service, generally referred to as a client, blocks until a reply is sent back from the server implementing the service
-
Communication in wide-area networks is inherently much less reliable than in local-area networks.
-
Wide-area systems, we need to develop separate services, such as naming and directory services to which queries can be sent. These support services, in turn, need to be scalable as well and in many cases no obvious solutions exist as we will encounter in later chapters.
Administrative scalability: Easily managed even if it spans many independent administrative organizations. Conflicting policies with respect to resource usage (and payment), management, and security needs to be solved. For example, for many years scientists have been looking for solutions to share their (often expensive) equipment in what is known as a computational grid. In these grids, a global distributed system is constructed as a federation of local distributed systems, allowing a program running on a computer at organization A to directly access resources at organization B.
If a distributed system expands to another domain, two types of security measures need to be taken.
-
First, the distributed system has to protect itself against malicious attacks from the new domain. Only read access to the file system in its original domain.
-
Second, the new domain has to protect itself against malicious attacks from the distributed system.
Scaling techniques
In DS, scalibility problems occur because of limited capacity of servers and network.
-
Scaling up: Increasing memory, upgrading CPUs, or replacing network modules
-
Scaling out: Expanding the distributed system by essentially deploying more machines, there are basically only three techniques can be applied:
- Hiding communication latencies: applicable in the case of geographical scalability. Instead of waiting for a response in the server-side use asynchronous communication. In interactive applications asynchronous communication cannot be applied. If this is the case, moving part of the computation that is normally done at the server to the client process requesting the service, could be one improvement.
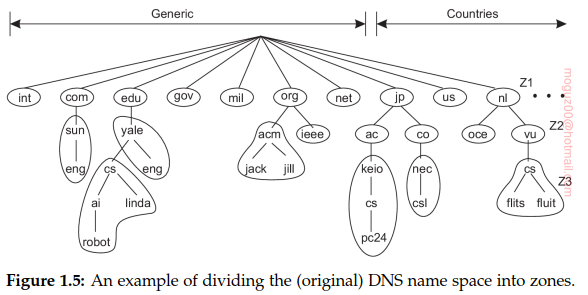
- Distribution of work Partitioning and distribution: taking a component, splitting it into smaller parts, and subsequently spreading those parts across the system. Internet Domain Name System (DNS). The names in each zone are handled by a single name server. Tree of domains, nonoverlapping zones. Naming service is distributed accross machines. Second example is, World Wide Web is partitioned and distributed across a few hundred million servers. Only because of this distribution of documents that the Web has been capable of scaling to its current size.
- Replication: Balance the load between components leading to better performance. Geographically widely dispersed systems, having a copy nearby can hide much of the communication latency problems. Caching is a special form of replication. Caching is making a copy of a resource, in the proximity of the client accessing that resource. Unlike replication, caching is a decision made by the client of a resource. Caching and replication leads to consistencyproblems.
Electronic stock exchanges and auctions, requires consistency. Replication requires global synchronization mechanism.
Pitfalls
Peter Deutsch, at the time working at Sun Microsystems, formulated these flaws as the following false assumptions that everyone makes when developing a distributed application for the first time:
• The network is reliable
• The network is secure
• The network is homogeneous
• The topology does not change
• Latency is zero
• Bandwidth is infinite
• Transport cost is zero
• There is one administrator
1.3 Types of distributed systems
Distributed computing systems, Distributed information systems, and Pervasive systems
High performance distributed computing
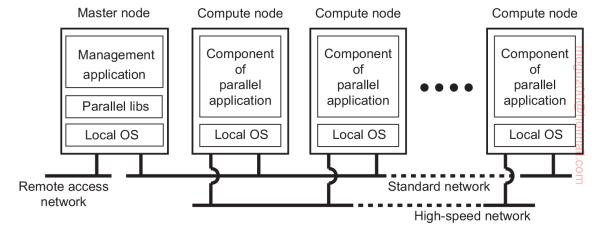
Cluster computing the underlying hardware consists of a collection of similar workstations or PCs, closely connected by means of a high-speed local-area network, each node runs the same operating system.
Grid computing This subgroup consists of distributed systems that are often constructed as a federation of computer systems, where each system may fall under a different administrative domain, and may be very different when it comes to hardware, software, and deployed network technology. Next step is to outsource entire infrastructure and this ends up in cloud computing.
Note 1.8 (More information: Parallel processing)
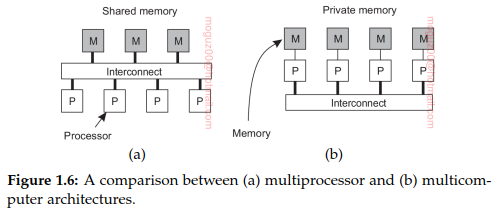
High-performance computing started with the introduction of multiprocessor machines. Multiple CPUs are organized in such a way that they all have access to the same physical memory. Multicomputer system several computers are connected through a network and there is no sharing of main memory. The shared-memory model proved to be highly convenient for improving the performance of programs and it was relatively easy to program. Distributed shared-memory multicomputers (DSM system). In essence, a DSM system allows a processor to address a memory location at another computer as if it were local memory
Cluster computing
Became popular when price/performance ratio of personal computers and workstations improved. One of the feature of CC is its homogeneity, the computers in a cluster are largely the same, have the same operating system, and are all connected through the same network.
Grid computing
No assumptions are made concerning similarity of hardware, operating systems, networks, administrative domains, security policies. Virtual organization
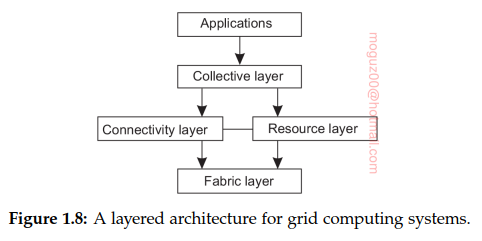
Fabric layer: Provides interfaces to local resources at a specific site.
Connectivity layer: Communication protocols for supporting grid transactions that span the usage of multiple resources.
Resource layer: Manages a single resource using the functions provided by the connectivity layer and calls directly the interfaces made available by the fabric layer.
Collective layer: Handling access to multiple resources and typically consists of services for resource discovery, allocation and scheduling of tasks onto multiple resources, data replication, and so on.
Application layer: Applications that operate within a virtual organization.
Service-oriented architecture - Open Grid Services Architecture (OGSA)
Cloud computing
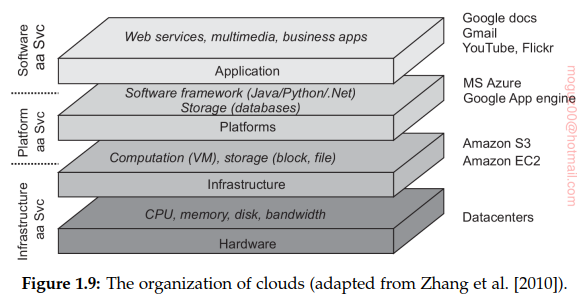
Utility computing by which a customer could upload tasks to a data center and be charged on a per-resource basis. Utility computing formed the basis for what is now called cloud computing. “Easily usable and accessible pool of virtualized resources”. Pay-per-use model in which guarantees are offered by means of customized service level agreements (SLAs).
-
Hardware: Manage the necessary hardware: processors, routers, but also power and cooling systems. Implemented at data centers and contains the resources that customers normally never get to see directly.
-
Infrastructure: Provide customers an infrastructure consisting of virtual storage and computing resources.
-
Platform: Platform layer provides to a cloud-computing customer what an operating system provides to application developers, namely the means to easily develop and deploy applications that need to run in a cloud. Amazon S3 storage system is offered to the application developer in the form of an API allowing (locally created) files to be organized and stored in buckets.
-
Application: Actual applications run in this layer and are offered to users for further customization. (text processors, spreadsheet applications, presentation applications, and so on). Applications are again executed in the vendor’s cloud.
- Infrastructure-as-a-Service (IaaS) covering the hardware and infrastructure layer
- Platform-as-a-Service (PaaS) covering the platform layer
- Software-as-a-Service (SaaS) in which their applications are covered
Cloud computing has some serious obstacles like: provider lock-in, security and privacy issues, and dependency on the availability of service.
Distributed information systems
For networked applications, interoperability turned out to be a painful experience. Apps communicate with each other and provide services to remote apps called clients. Distributed transactions. This lead to Enterprise Application Integration (EAI).
Distributed transaction processing
Operations on a database are carried out in the form of transactions. Remote procedure calls(RPCs), that is, procedure calls to remote servers, are often also encapsulated in a transaction, leading to what is known as a transactional RPC.
Example primitives for transactions:
| Primitive | Description |
| BEGIN_TRANSACTION | Mark the start of a transaction |
| END_TRANSACTION | Terminate the transaction and try to commit |
| ABORT_TRANSACTION | Kill the transaction and restore the old values |
| READ | Read data from a file, a table, or otherwise |
| WRITE | Write data to a file, a table, or otherwise |
All-or-nothing property of transactions is also called ACID properties:
- Atomic: To the outside world, the transaction happens indivisibly
- Consistent: The transaction does not violate system invariants
- Isolated: Concurrent transactions do not interfere with each other
- Durable: Once a transaction commits, the changes are permanent
Number of subtransactions, jointly forming a nested transaction.
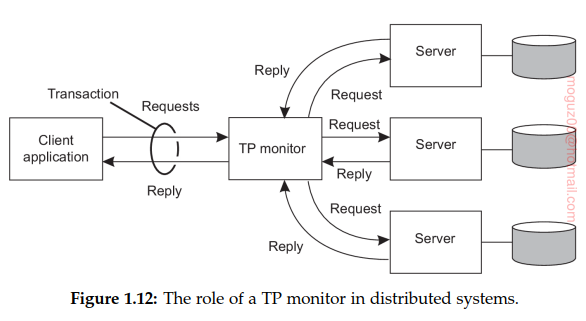
The component that handled distributed (or nested) transactions formed the core for integrating applications at the server or database level. This component was called a transaction processing monitor or TP monitor for short. TP monitor coordinated the commitment of subtransactions following a standard protocol known as distributed commit.
Enterprise application integration
Remote procedure calls (RPC) an application component can effectively send a request to another application component by doing a local procedure call, which results in the request being packaged as a message and sent to the callee.
Remote method invocations (RMI) An RMI is essentially the same as an RPC, except that it operates on objects instead of functions.
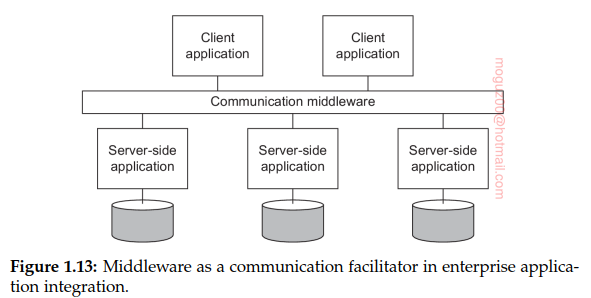
RPC and RMI have the disadvantage that the caller and callee both need to be up and running at the time of communication. This lead to message-oriented middleware, or simply MOM.
Publish/subscribe systems applications send messages to logical contact points, often described by means of a subject, then applications can indicate their interest for a specific type of message, after which the communication middleware will take care that those messages are delivered to those applications.
Note 1.10 (More information: On integrating applications)
File transfer: things that need to be agreed upon:
- File format and layout:
- File management:
- Update propagation:
Shared database: two major drawbacks.
- There is still a need to design a common data schema
- When there are many reads and updates, a shared database can easily become a performance bottleneck.
Remote procedure call: an RPC allows an application A to make use of the information available only to application B, without giving A direct access to that information
Messaging: eventually the request is delivered, and if needed, that a response is eventually returned as well.
Pervasive systems
Pervasive means “her tarafa yayılan” in Turkish. Introduction of mobile and embedded computing devices, leading to what are generally referred to as pervasive systems. Separation between users and system components is much more blurred. There is often no single dedicated interface, such as a screen/keyboard combination. Instead, a pervasive system is often equipped with many sensors that pick up various aspects of a user’s behavior. Likewise, it may have a myriad of actuators to provide information and feedback, often even purposefully aiming to steer behavior.
Devices are characterized as being small, battery-powered, mobile, and having only a wireless connection. Internet of Things.
Ubiquitous computing systems
Ubiquitous means “her yerde birden bulunan” in Turkish. User is continuously interacting with the system, often not even being aware that interaction is taking place.
-
(Distribution) Devices are networked, distributed, and accessible in a transparent manner
-
(Interaction) Interaction between users and devices is highly unobtrusive
-
(Context awareness) The system is aware of a user’s context in order to optimize interaction
-
(Autonomy) Devices operate autonomously without human intervention, and are thus highly self-managed
Address allocation: Dynamic Host Configuration Protocol (DHCP)
Adding devices: It should be easy to add devices to an existing system. Universal Plug and Play Protocol (UPnP)
Automatic updates:
-
(Intelligence) The system as a whole can handle a wide range of dynamic actions and interactions
Mobile computing systems
-
Mobile implies wireless communication.
-
The location of a device is assumed to change over time.
Disruption-tolerant networks: networks in which connectivity between two nodes can simply not be guaranteed.
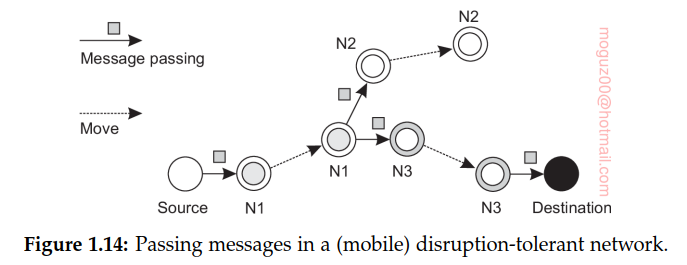
With the increasing interest in complex social networks and the explosion of the use of smartphones, combine analysis of social behavior and information dissemination in so-called pocket-switched networks where nodes are formed by people (or actually, their mobile devices), and links are formed when two people encounter each other, allowing their devices to exchange data.
Sensor networks
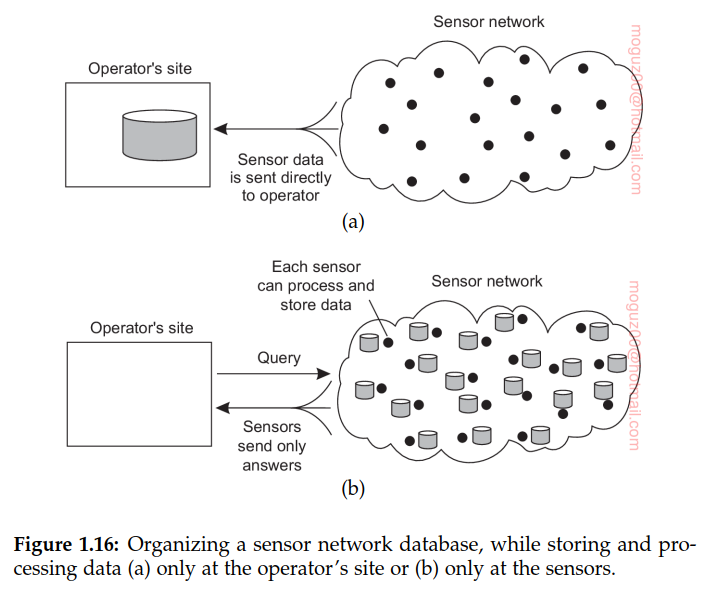
First, sensors do not cooperate but simply send their data to a centralized database located at the operator’s site. The other extreme is to forward queries to relevant sensors and to let each compute an answer, requiring the operator to aggregate the responses. The first one requires that sensors send all their measured data through the network, which may waste network resources and energy. The second solution may also be wasteful as it discards the aggregation capabilities of sensors which would allow much less data to be returned to the operator. What is needed are facilities for in-network data processing, similar to the previous example of abstract regions.
Chapter 2. Architectures
The organization of a distributed system can be done one the logical organization of the collection of software components, and second the actual physical realization.
2.1 Architectural styles
A component is a modular unit with well-defined required and provided interfaces that is replaceable within its environment. Connector, which is generally described as a mechanism that mediates communication, coordination, or cooperation among components.
- Layered architectures
- Object-based architectures
- Resource-centered architectures
- Event-based architectures
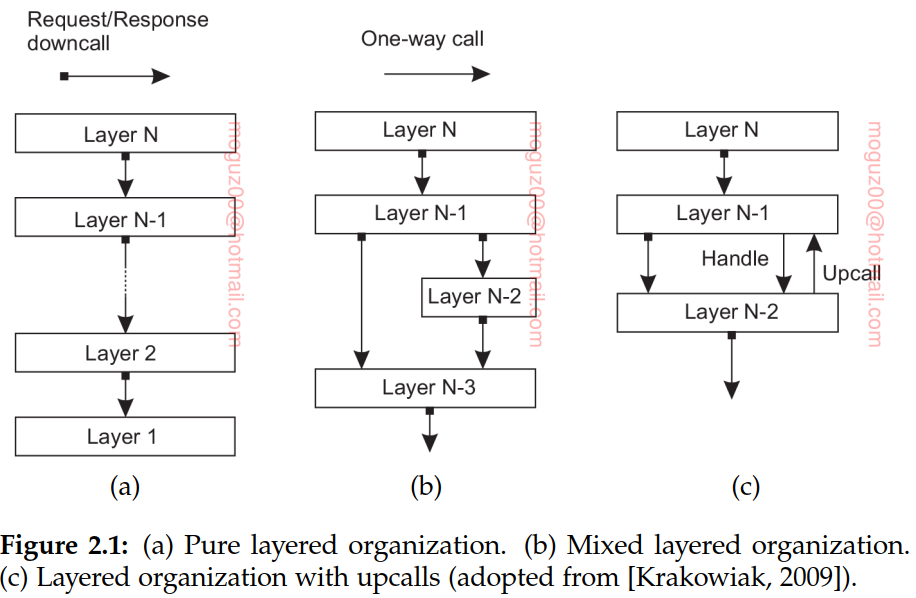
Layered architecture:
Layered fashion where a component at layer Lj can make a downcall to a component at a lower-level layer Li (with i < j) and generally expects a response. Only in exceptional cases will an upcall be made to a higher-level component.
Layered communication protocols
Communication-protocol stacks, each layer implements one or several communication services allowing data to be sent from a destination to one or several targets. To this end, each layer offers an interface specifying the functions that can be called. In principle, the interface should completely hide the actual implementation of a service. Another important concept in the case of communication is that of a (communication) protocol, which describes the rules that parties will follow in order to exchange information. It is important to understand the difference between a service offered by a layer, the interface by which that service is made available, and the protocol that a layer implements to establish communication.
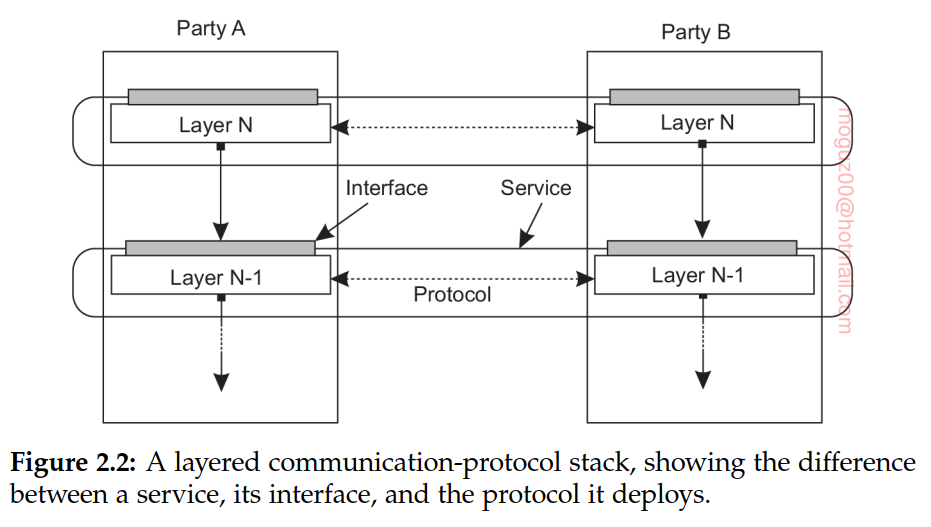
Transmission Control Protocol (TCP). The protocol specifies which messages are to be exchanged for setting up or tearing down a connection, what needs to be done to preserve the ordering of transferred data, and what both parties need to do to detect and correct data that was lost during transmission.
Application layering
- The application-interface level: a part that handles interaction with a user or some external application
- The processing level: a middle part that generally contains the core functionality of the application
- The data level: a part that operates on a database or file system
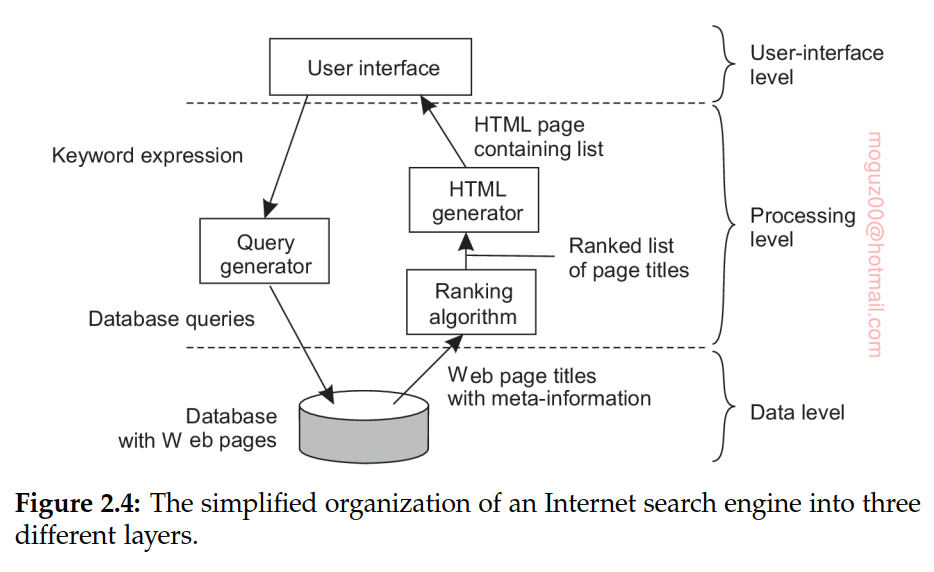
In data level data is persistent, even if no application is running, data will be stored somewhere for next use.
Object-based and service-oriented architectures
Object-based architectures
Each object corresponds to a component, and these components are connected through a procedure call mechanism. A procedure call can also take place over a network, that is, the calling object need not be executed on the same machine as the called object.
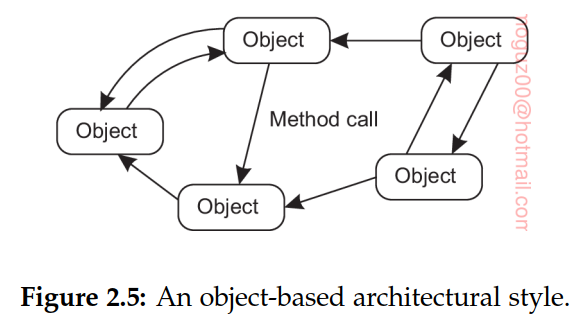
Data encapsulating (object’s state) and the operations that can be performed on that data (object’s methods). The interface offered by an object conceals implementation details.
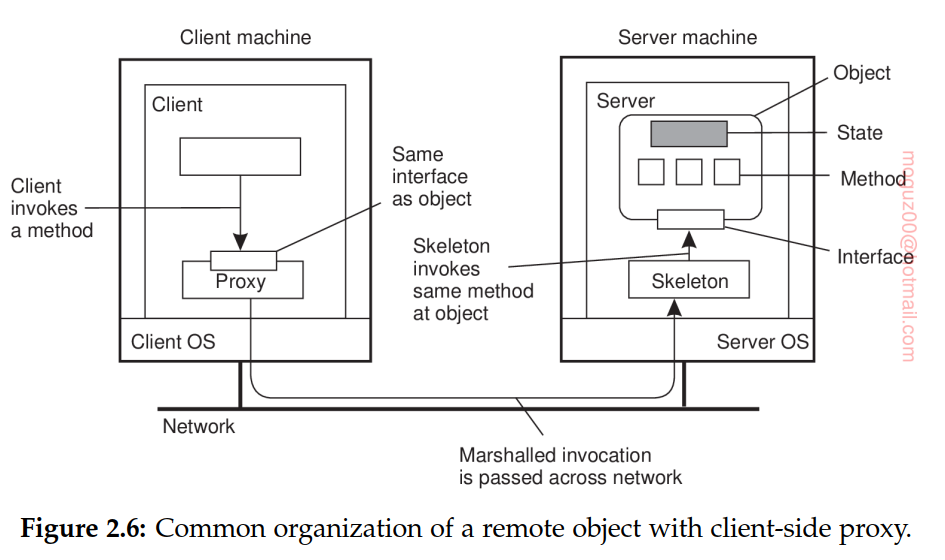
Distributed objects state is not distributed: it resides at a single machine. Only the interfaces implemented by the object are made available on other machines. Such objects are also referred to as remote objects.
In a service-oriented architecture, a distributed application or system is essentially constructed as a composition of many different services. Not all of these services may belong to the same administrative organization. Developing a distributed system is partly one of service composition, and making sure that those services operate in harmony
Resource-based architectures
Distributed system is huge collection of resources that are individually managed by components. Representational State Transfer (REST). There are four key characteristics of what are known as RESTful
-
Resources are identified through a single naming scheme
-
All services offer the same interface, consisting of at most four operations,
-
Messages sent to or from a service are fully self-described
-
After executing an operation at a service, that component forgets everything about the caller The last property is also referred to as a stateless execution,

Amazon’s Simple Storage Service (Amazon S3): objects, which are essentially the equivalent of files, and buckets, the equivalent of directories. Uniform Resource Identifier (URI): http://BucketName.s3.amazonaws.com/ObjectName
Publish-subscribe architectures
Processes can more easily join or leave. Dependencies between processes become as loose as possible.
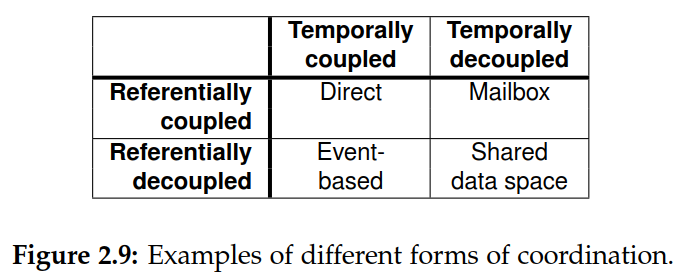
Referential Coupling - Know name or identifier of the process Temporarily Coupling - Both processes must be up and running
- Direct Coordination - Cell phone
- Mailbox Coordination - Mails
- Event-Based Coordination - Publish a notification and subscribe
- Shared Data Space -
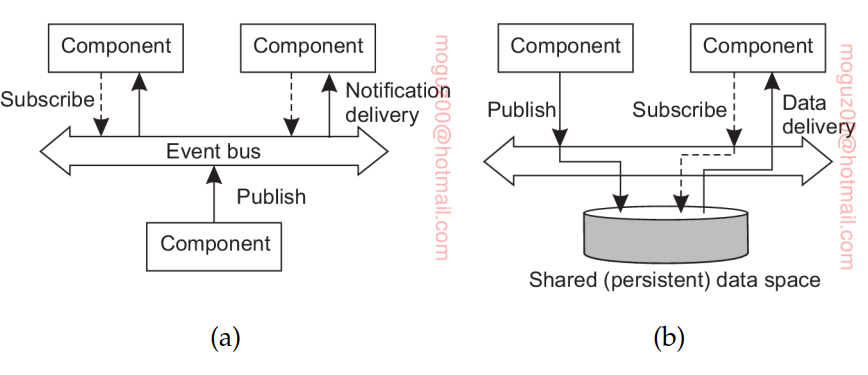
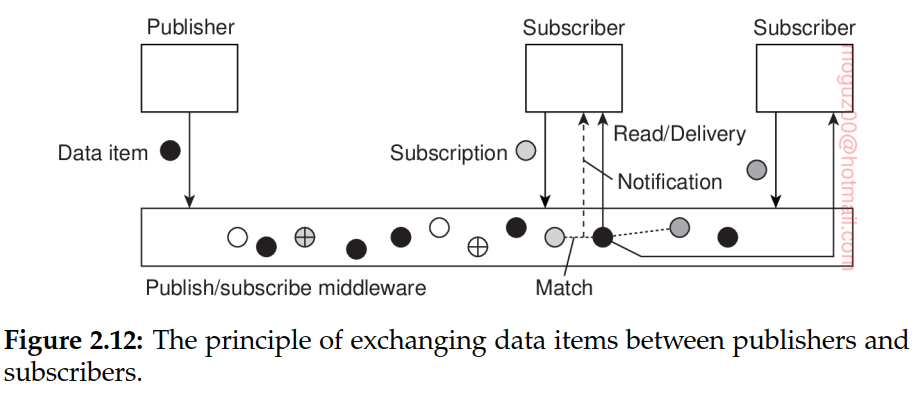
Feature of publish-subscribe systems is that communication takes place by describing the events that a subscriber is interested in. (attribute, value) pairs topic-based publish-subscribe systems. (attribute, range) pairs content-based publish-subscribe systems. In this case, the specified attribute is expected to take on values within a specified range.
When subscriptions are matched, there are two possible scenarios. In the first case, the middleware may decide to forward the published notification, along with the associated data, to its current set of subscribers, that is, processes with a matching subscription. As an alternative, the middleware can also forward only a notification at which point subscribers can execute a read operation to retrieve the associated data item.
2.2 Middleware organization
Design patterns that are often applied to the organization of middleware: wrappers and interceptors. Both aim achieving openness.
Wrappers
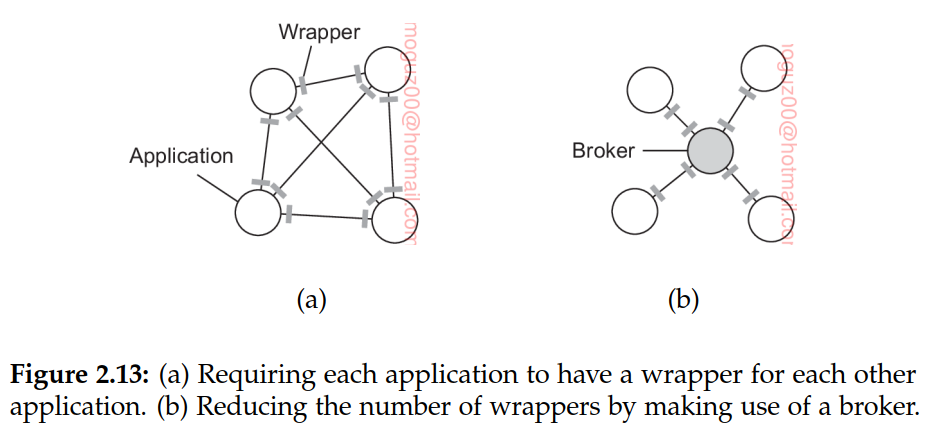
The interfaces offered by the legacy component are most likely not suitable for all applications. A wrapper or adapter is a special component that offers an interface acceptable to a client application, of which the functions are transformed into those available at the component. Wrappers have always played an important role in extending systems with existing components.
With N applications we would, in theory, need to develop N × (N − 1) = O(N2) wrappers. Broker, which is logically a centralized component that handles all the accesses between different applications.
Interceptors
Interceptor(durdurucu, yol kesen in Turkish) is nothing but a software construct that will break the usual flow of control and allow other (application specific) code to be executed. request-level interceptor - message-level interceptor
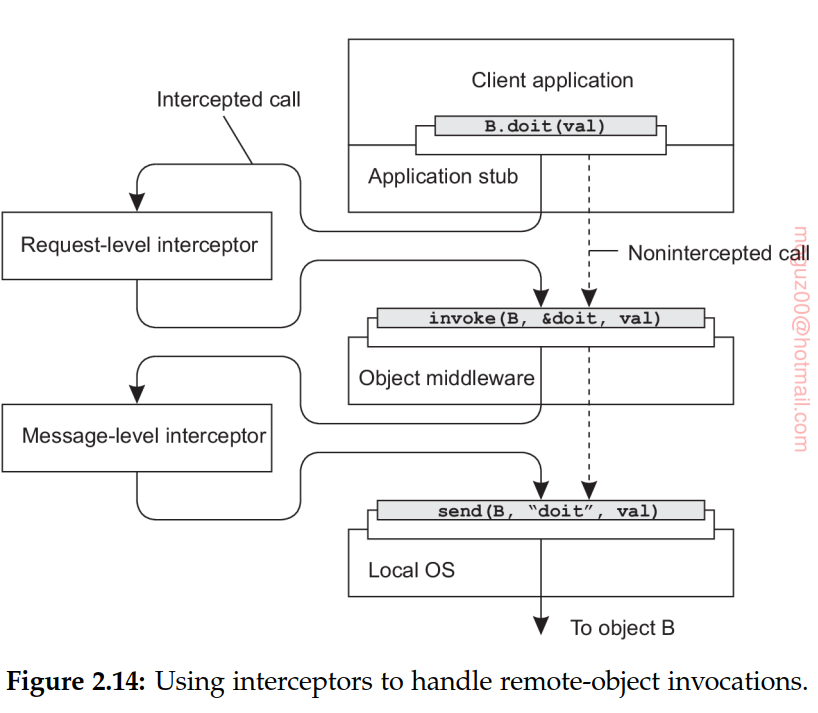
Modifiable middleware
Designers of middleware to consider the construction of adaptive software. Replacing software components at runtime is an example of modifying a system. A system may either be configured statically at design time, or dynamically at runtime.
2.3 System architecture
Centralized and decentralized organizations, as well as various hybrid forms.
Centralized organizations
Clients that request services from servers helps understanding and managing the complexity of distributed systems.
Simple client-server architecture
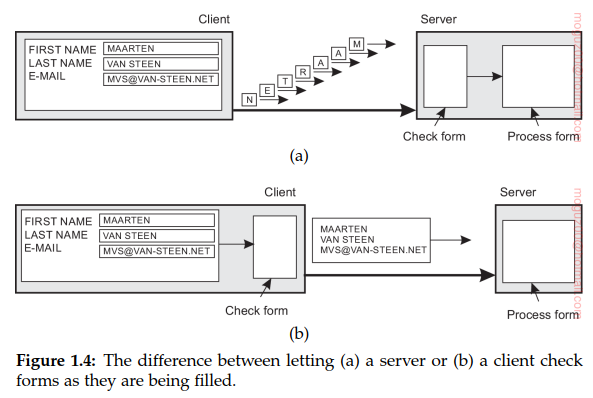
A server is a process implementing a specific service, for example, a file system service or a database service. A client is a process that requests a service from a server by sending it a request and subsequently waiting for the server’s reply. This client-server interaction, also known as request-reply behavior.
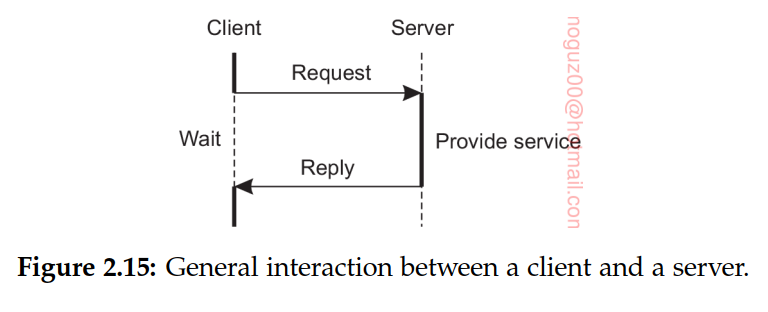
When an operation can be repeated multiple times without harm, it is said to be idempotent.
Virtually all Internet application protocols are based on reliable TCP/IP connections. In this case, whenever a client requests a service, it first sets up a connection to the server before sending the request. The server generally uses that same connection to send the reply message, after which the connection is torn down. The trouble may be that setting up and tearing down a connection is relatively costly, especially when the request and reply messages are small.
Multitiered Architectures
- A client machine containing only the programs implementing (part of) the user-interface level
- A server machine containing the rest, that is, the programs implementing the processing and data level
First step, we make a distinction between only two kinds of machines: client machines and server machines, leading to what is also referred to as a (physically) two-tiered architecture.
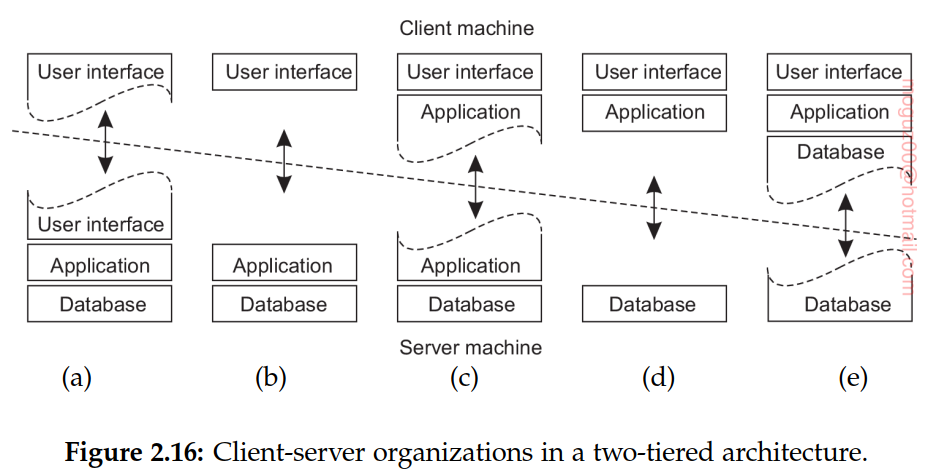
From a systems-management perspective, having what are called fat clients is not optimal. Instead the thin clients as represented by the organizations shown in Figure 2.16(a)–(c) are much easier, perhaps at the cost of less sophisticated user interfaces and client-perceived performance.
Fat clients: office suites, many multimedia applications require that processing is done on the client’s side.
Server may sometimes need to act as a client, this leads to (physically) three-tiered architecture
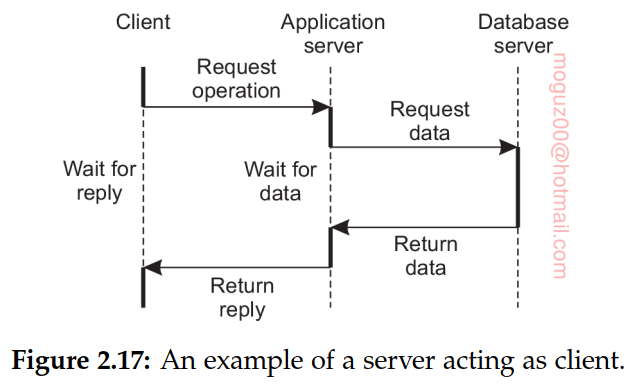
Examples: Transaction processing. Organization of Web sites. Web server acts as an entry point to a site, passing requests to an application server where the actual processing takes place. This application server, in turn, interacts with a database server.
Decentralized organizations: peer-to-peer systems
A client-server application as a multitiered architecture. We refer to this type of distribution as vertical distribution. The characteristic feature of vertical distribution is that it is achieved by placing logically different components on different machines. The term is related to the concept of vertical fragmentation as used in distributed relational databases, where it means that tables are split columnwise, and subsequently distributed across multiple machines
Distribution of the clients and the servers that counts, which we refer to as horizontal distribution. In this type of distribution, a client or server may be physically split up into logically equivalent parts, but each part is operating on its own share of the complete data set, thus balancing the load.
Processes that constitute a peer-to-peer system are all equal interaction between processes is symmetric: each process will act as a client and a server at the same time acting as a servant
Structured peer-to-peer systems
Nodes (processes) are organized in an overlay that adheres to a specific, deterministic topology: a ring, a binary tree, a grid. Each data item that is to be maintained by the system, is uniquely associated with a key, and that this key is subsequently used as an index. To this end, it is common to use a hash function, so that we get:
key(data item) = hash(data item’s value)
A hypercube is an n-dimensional cube.
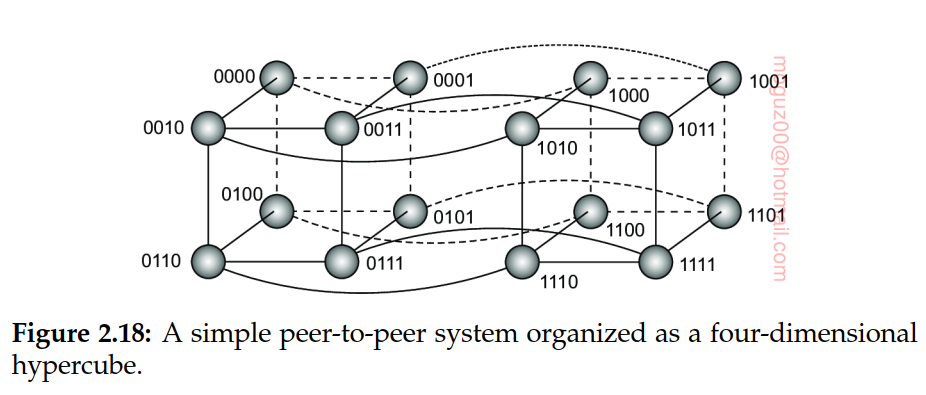
Unstructured peer-to-peer systems
Each node maintains an ad hoc list of neighbors. The resulting overlay resembles what is known as a random graph: a graph in which an edge hu, vi between two nodes u and v exists only with a certain probability P[hu, vi]
Flooding: In the case of flooding, an issuing node u simply passes a request for a data item to all its neighbors time-to-live or TTL value, giving the maximum number of hops a request is allowed to be forwarded
Random walks: At the other end of the search spectrum, an issuing node u can simply try to find a data item by asking a randomly chosen neighbor,
Hierarchically organized peer-to-peer networks
Many peer-to-peer systems have proposed to make use of special nodes that maintain an index of data items. A collaborative content delivery network (CDN), nodes may offer storage for hosting copies of Web documents allowing Web clients to access pages nearby, and thus to access them quickly. Nodes such as those maintaining an index or acting as a broker are generally referred to as super peers. Every regular peer, now referred to as a weak peer, is connected as a client to a super peer.
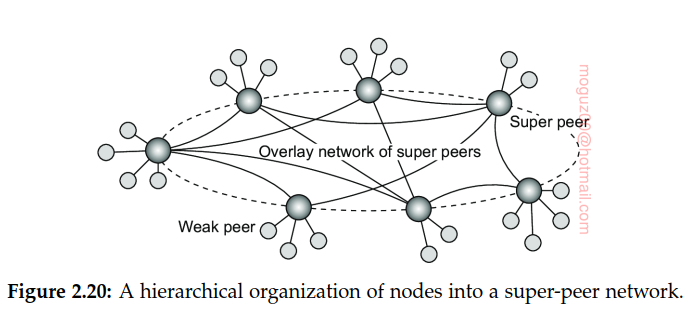
In the case of file-sharing networks, it may be better for a weak peer to attach to a super peer that maintains an index of files that the weak peer is currently interested in. In that case, chances are bigger that when a weak peer is looking for a specific file, its super peer will know where to find it.
With super-peer networks a new problem is introduced, namely how to select the nodes that are eligible to become super peer. This problem is closely related to the leader-election problem.
Hybrid Architectures
Some specific classes of distributed systems in which client-server solutions are combined with decentralized architectures.
Edge-server systems
These systems are deployed on the Internet where servers are placed “at the edge” of the network. This edge is formed by the boundary between enterprise networks and the actual Internet, for example, as provided by an Internet Service Provider (ISP). Likewise, where end users at home connect to the Internet through their ISP, the ISP can be considered as residing at the edge of the Internet.
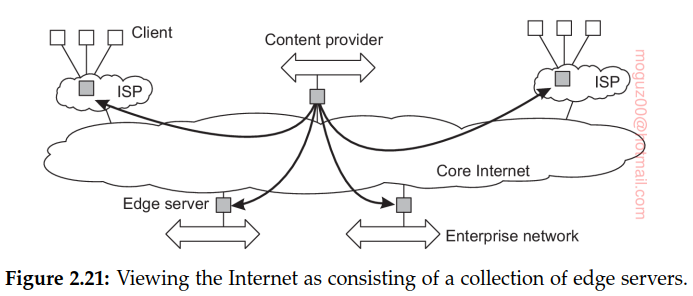
A step further: taking cloud computing as implemented in a data center as the core, additional servers at the edge of the network are used to assist in computations and storage, essentially leading to distributed cloud systems. In the case of fog computing, even end-user devices form part of the system and are (partly) controlled by a cloud-service provider.
Collaborative distributed systems
BitTorrent is a peer-to-peer file downloading system. The basic idea is that when an end user is looking for a file, he downloads chunks of the file from other users until the downloaded chunks can be assembled together yielding the complete file. An important design goal was to ensure collaboration. In most file-sharing systems, a significant fraction of participants merely download files but otherwise contribute close to nothing, a phenomenon referred to as free riding. To prevent this situation, in BitTorrent a file can be downloaded only when the downloading client is providing content to someone else.
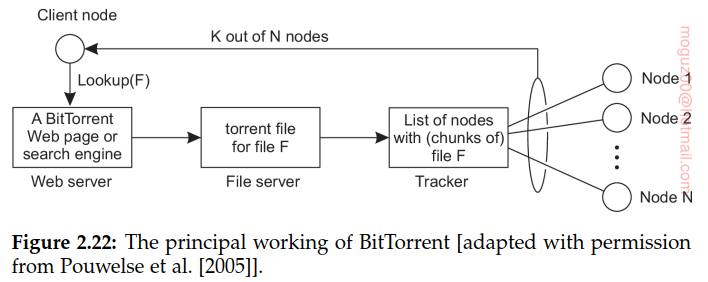
A torrent file contains the information that is needed to download a specific file. In particular, it contains a link to what is known as a tracker, which is a server that is keeping an accurate account of active nodes that have (chunks of) the requested file.
2.4 Example architectures
The Network File System
Many distributed files systems are organized along the lines of client-server architectures, with Sun Microsystem’s Network File System (NFS) being one of the most widely-deployed ones for Unix systems.
The model underlying NFS and similar systems is that of a remote file service. In this model, clients are offered transparent access to a file system that is managed by a remote server. However, clients are normally unaware of the actual location of files.
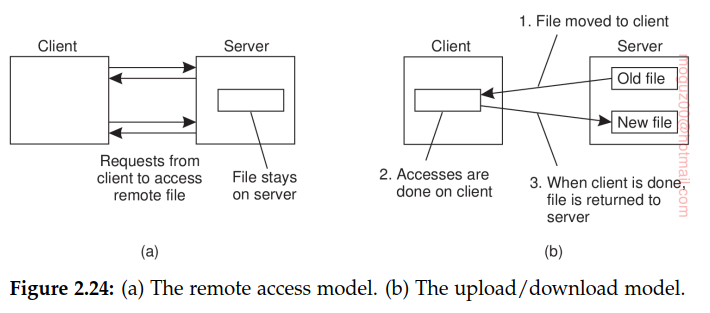
Remote access model: the client is offered only an interface containing various file operations, but the server is responsible for implementing those operations.
Upload/download model a client accesses a file locally after having downloaded it from the server. Internet’s FTP service
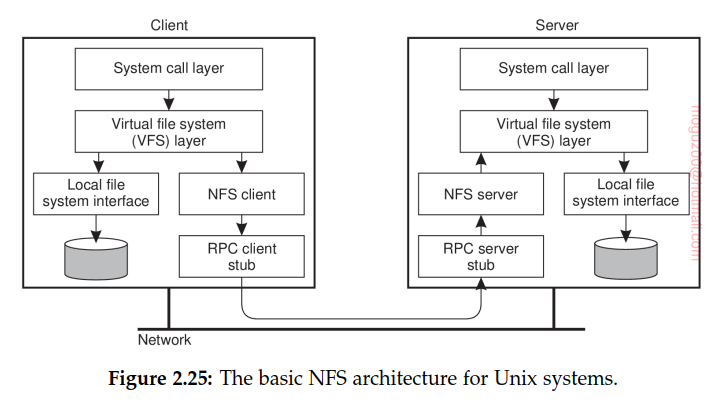
Virtual File System (VFS), which by now is a de facto standard for interfacing to different (distributed) file systems. NFS, operations on the VFS interface are either passed to a local file system, or passed to a separate component known as the NFS client, which takes care of handling access to files stored at a remote server. In NFS, all client-server communication is done through so-called remote procedure calls (RPCs). The whole idea of the VFS is to hide the differences between various file systems. The NFS server is responsible for handling incoming client requests.
The Web
Simple Web-based systems
The simplest way to refer to a document is by means of a reference called a Uniform Resource Locator (URL). It specifies where a document is located by embedding the DNS name of its associated server along with a file name by which the server can look up the document in its local file system. Furthermore, a URL specifies the application-level protocol for transferring the document across the network. The communication between a browser and Web server is standardized: they both adhere to the HyperText Transfer Protocol (HTTP).
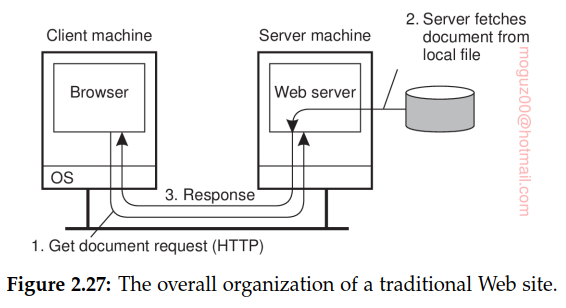
HyperText Markup Language, or simply HTML. In that case, the document includes various instructions expressing how its content should be displayed, similar to what one can expect from any decent word processing system. In particular, they can have complete programs embedded of which Javascript is the one most often deployed.
Multitiered architectures
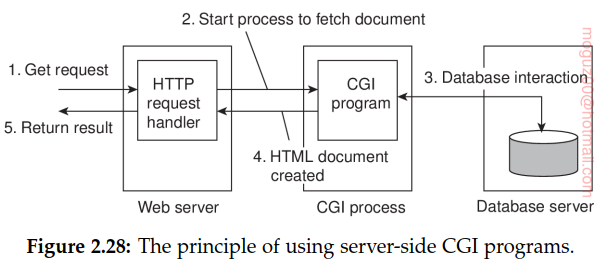
Common Gateway Interface or simply CGI. CGI defines a standard way by which a Web server can execute a program taking user data as input.
2.5 Summary
Distributed systems can be organized in many different ways. We can make a distinction between software architecture and system architecture. The latter considers where the components that constitute a distributed system are placed across the various machines. The former is more concerned about the logical organization of the software: how do components interact, in what ways can they be structured, how can they be made independent, and so on.
A keyword when talking about architectures is architectural style. A style reflects the basic principle that is followed in organizing the interaction between the software components comprising a distributed system. Important styles include layering, object-based styles, resource-based styles, and styles in which handling events are prominent.
There are many different organizations of distributed systems. An important class is where machines are divided into clients and servers. A client sends a request to a server, who will then produce a result that is returned to the client. The client-server architecture reflects the traditional way of modularizing software in which a module calls the functions available in another module. By placing different components on different machines, we obtain a natural physical distribution of functions across a collection of machines.
Client-server architectures are often highly centralized. In decentralized architectures we often see an equal role played by the processes that constitute a distributed system, also known as peer-to-peer systems. In peer-to-peer systems, the processes are organized into an overlay network, which is a logical network in which every process has a local list of other peers that it can communicate with. The overlay network can be structured, in which case deterministic schemes can be deployed for routing messages between processes. In unstructured networks, the list of peers is more or less random, implying that search algorithms need to be deployed for locating data or other processes.
In hybrid architectures, elements from centralized and decentralized or- ganizations are combined. A centralized component is often used to handle initial requests, for example to redirect a client to a replica server, which, in turn, may be part of a peer-to-peer network as is the case in BitTorrent-based systems.
Chapter 3 Processes
Processes: program in execution. From an operating-system perspective, the management and scheduling of processes are perhaps the most important issues to deal with.
3.1 Threads
Having a finer granularity in the form of multiple threads of control per process makes it much easier to build distributed applications and to get better performance.
Introduction to threads
To execute a program, an operating system creates a number of virtual processors, each one for running a different program. To keep track of these virtual processors,the operating system has a process table, containing entries to store CPU register values, memory maps, open files, accounting information, privileges, etc. Jointly, these entries form a process context.
A process context can be viewed as the software analog of the hardware’s processor context. The latter consists of the minimal information that is automatically stored by the hardware to handle an interrupt, and to later return to where the CPU left off. The processor context contains at least the program counter, but sometimes also other register values such as the stack pointer.
A process is often defined as a program in execution, that is, a program that is currently being executed on one of the operating system’s virtual processors.
A thread context often consists of nothing more than the processor context, along with some other information for thread management.
The performance of a multithreaded application need hardly ever be worse than that of its single-threaded counterpart. In fact, in many cases, multithreading even leads to a performance gain. Second, because threads are not automatically protected against each other the way processes are, development of multithreaded applications requires additional intellectual effort.
Registers of the memory management unit (MMU) and invalidate address translation caches such as in the translation lookaside buffer (TLB).
Thread usage in nondistributed systems
In a single-threaded process, whenever a blocking system call is executed, the process as a whole is blocked.
It becomes possible to exploit parallelism when executing the program on a multiprocessor or multicore system.
Multithreading is also useful in the context of large applications. Collection of cooperating programs, each to be executed by a separate process. This approach is typical for a Unix environment. Cooperation between programs is implemented by means of interprocess communication (IPC) mechanisms. For Unix systems, these mechanisms typically include (named) pipes, message queues, and shared memory segments. The major drawback of all IPC mechanisms is that communication often requires relatively extensive context switching.
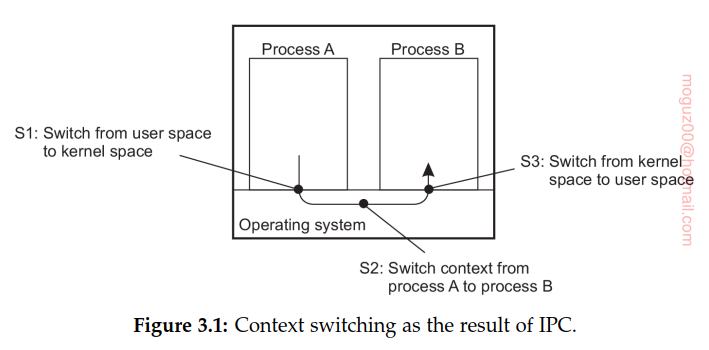
Software engineering reason to use threads: many applications are simply easier to structure as a collection of cooperating threads.
Thread implementation
Thread package to create and destroy threads as well as operations on synchronization variables such as mutexes and condition variables.
Basically two approaches to implement a thread package. The first approach is to construct a thread library that is executed entirely in user space. The second approach is to have the kernel be aware of threads and schedule them.
Many-to-one threading model: multiple threads are mapped to a single schedulable entity.
One-to-one threading model in which every thread is a schedulable entity.
Using processes instead of threads has the important advantage of separating the data space: each process works on its own part of data and is protected from interference from others through the operating system. Thread programming is considered to be notoriously difficult because the developer is fully responsible for managing concurrent access to shared data.
Threads in distributed systems
Important property of threads is that they can provide a convenient means of allowing blocking system calls without blocking the entire process in which the thread is running.
Multithreaded clients
The round-trip delay in a wide-area network can easily be in the order of hundreds of milliseconds, or sometimes even seconds.
To hide communication latencies as much as possible, some browsers start displaying data while it is still coming in.
Web servers have been replicated across multiple machines, where each server provides exactly the same set of Web documents. The replicated servers are located at the same site, and are known under the same name. When a request for a Web page comes in, the request is forwarded to one of the servers, often using a round-robin strategy or some other load-balancing technique.
When using a multithreaded client, connections may be set up to different replicas, allowing data to be transferred in parallel, effectively establishing that the entire Web document is fully displayed in a much shorter time than with a nonreplicated server. This approach is possible only if the client can handle truly parallel streams of incoming data. Threads are ideal for this purpose.
- Note that an active thread is not necessarily running; it may be blocked waiting for an I/O request to complete
Multithreaded servers
Using multithread is more beneficial in the server side. To understand the benefits of threads for writing server code, consider the organization of a file server that occasionally has to block waiting for the disk. The file server normally waits for an incoming request for a file operation, subsequently carries out the request, and then sends back the reply. One possible, and particularly popular organization is shown in Figure 3.4. Here one thread, the dispatcher, reads incoming requests for a file operation. The requests are sent by clients to a well-known end point for this server. After examining the request, the server chooses an idle (i.e., blocked) worker thread and hands it the request
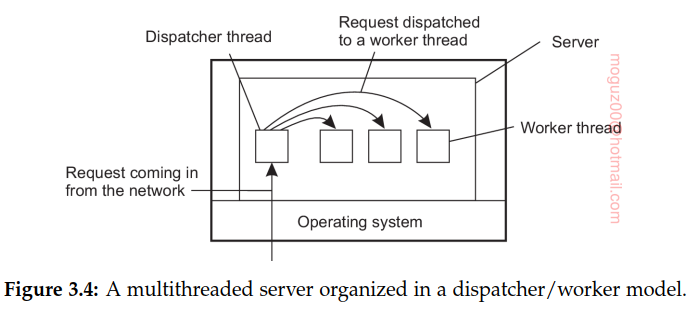
A multithreaded file server and a single-threaded file server. A third alternative is to run the server as a big single-threaded finite-state machine.
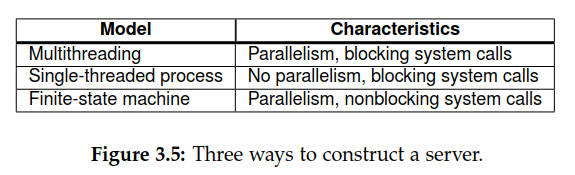
Threads make it possible to retain the idea of sequential processes that make blocking system calls and still achieve parallelism. The finite-state machine approach achieves high performance through parallelism, but uses nonblocking calls, which is generally hard to program and thus to maintain.
Instead of using threads, we can also use multiple processes to organize a server (leading to the situation that we actually have a multiprocess server). The advantage is that the operating system can offer more protection against accidental access to shared data. However, if processes need to communicate a lot, we may see a noticeable adverse affect on performance in comparison to using threads.
3.2 Virtualization
Threads and processes build (pieces of) programs that appear to be executed simultaneously. In single processor machine by rapidly switching between threads and processes, the illusion of parallelism is created. Separation between having a single CPU and being able to pretend there are more can be extended to other resources as well, leading to what is known as resource virtualization.
Principle of virtualization
Every (distributed) computer system offers a programming interface to higher-level software. There are many different types of interfaces, ranging from the basic instruction set as offered by a CPU to the vast collection of application programming interfaces that are shipped with many current middleware systems. In its essence, virtualization deals with extending or replacing an existing interface so as to mimic the behavior of another system.
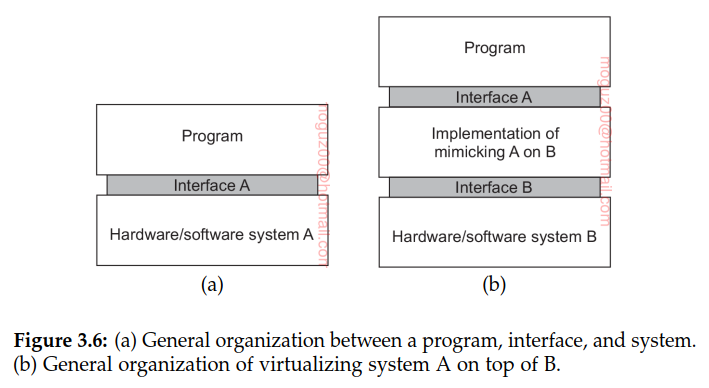
Virtualization and distributed systems
Virtualization can help a lot: the diversity of platforms and machines can be reduced by essentially letting each application run on its own virtual machine, possibly including the related libraries and operating system, which, in turn, run on a common platform.
High degree of portability and flexibility. Content delivery networks that can easily support replication of dynamic contentç management becomes much easier if edge servers would support virtualization, allowing a complete site, including its environment to be dynamically copied.
Types of virtualization
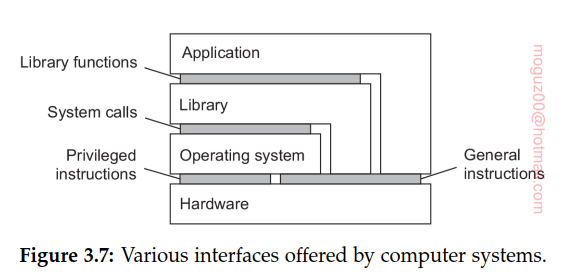
Computer systems generally offer four different types of interfaces, at three different levels:
- An interface between the hardware and software, referred to as the instruction set architecture (ISA), forming the set of machine instructions. This set is divided into two subsets: • Privileged instructions, which are allowed to be executed only by the operating system. • General instructions, which can be executed by any program.
- An interface consisting of system calls as offered by an operating system.
- An interface consisting of library calls, generally forming what is known as an application programming interface (API). In many cases, the aforementioned system calls are hidden by an API.
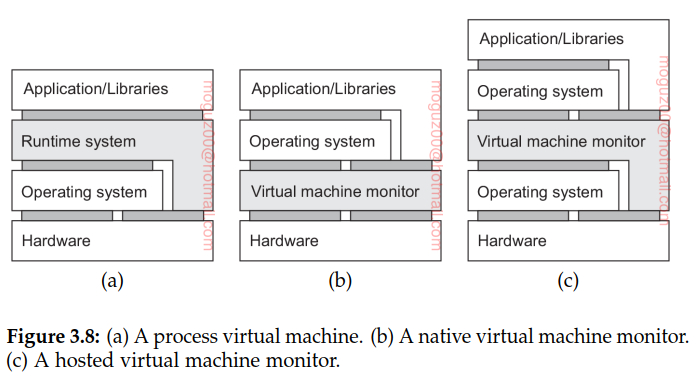
Virtualization can take place in two different ways:
-
Runtime system that essentially provides an abstract instruction set that is to be used for executing applications. Process virtual machine, stressing that virtualization is only for a single process.
-
Provide a system that is implemented as a layer shielding the original hardware, but offering the complete instruction set of that same (or other hardware) as an interface. This leads to what is known as a native virtual machine monitor. It is called native because it is implemented directly on top of the underlying hardware. Note that the interface offered by a virtual machine monitor can be offered simultaneously to different programs. As a result, it is now possible to have multiple, and different guest operating systems run independently and concurrently on the same platform.
-
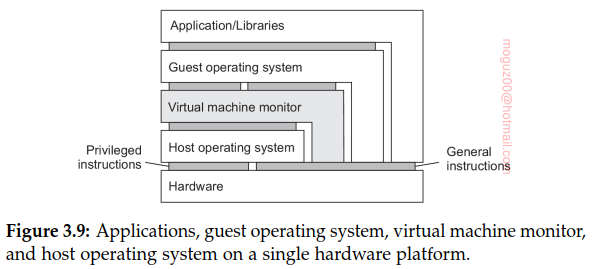
A native virtual machine monitor will have to provide and regulate access to various resources, like external storage and networks. Like any operating system, this implies that it will have to implement device drivers for those resources. Rather than doing all this effort anew, a hosted virtual machine monitor will run on top of a trusted host operating system. In this case, the virtual machine monitor can make use of existing facilities provided by that host operating system. It will generally have to be given special privileges instead of running as a user-level application. Using a hosted virtual machine monitor is highly popular in modern distributed systems such as data centers and clouds.
Note 3.5 (Advanced: On the performance of virtual machines)
For any conventional computer, a virtual machine monitor may be constructed if the set of sensitive instructions for that computer is a subset of the set of privileged instructions.
Application of virtual machines to distributed systems
From the perspective of distributed systems, the most important application of virtualization lies in cloud computing.
- Infrastructure-as-a-Service (IaaS) covering the basic infrastructure
- Platform-as-a-Service (PaaS) covering system-level services
- Software-as-a-Service (SaaS) containing actual applications
Virtualization plays a key role in IaaS. Instead of renting out a physical machine, a cloud provider will rent out a virtual machine (monitor) that may, or may not, be sharing a physical machine with other customers. The beauty of virtualization is that it allows for almost complete isolation between customers, who will indeed have the illusion that they have just rented a dedicated physical machine.
Amazon Elastic Compute Cloud, or simply EC2. There is a (large) number of pre-configured machine images available, referred to as Amazon Machine Images, or simply AMIs. An AMI is an installable software package consisting of an operating-system kernel along with a number of services. An example of a simple, basic AMI is a LAMP image, consisting of a Linux kernel, the Apache Web server, a MySQL database system, and PHP libraries. More elaborate images containing additional software are also available, as well as images based on other Unix kernels or Windows. In this sense, an AMI is essentially the same as a boot disk. Where EC2 Instances are running: regions provided by Amazon (US, South America, Europe, Asia)
Two ip’s of the EC2’s. One is private used for internal communication between instances and public one allows internet clients to connect. The public address is mapped to the private one using standard Network Address Translation (NAT) technology.
The EC2 environment in which an instance is executed provides different levels of the following services:
- CPU: allows to select the number and type of cores, including GPUs
- Memory: defines how much main memory is allocated to an instance
- Storage: defines how much local storage is allocated
- Platform: distinguishes between 32-bit or 64-bit architectures
- Networking: sets the bandwidth capacity that can be used
The local storage that comes with an instance is transient: when the instance stops, all the data stored locally is lost. In order to prevent data loss, a customer will need to explicitly save data to persistent store, for example, by making use of Amazon’s Simple Storage Service (S3). An alternative is to attach a storage device that is mapped to Amazon’s Elastic Block Store (Amazon EBS). EBS is mounting a harddrive and can be used in other instances.
3.3 Clients
Networked user interfaces
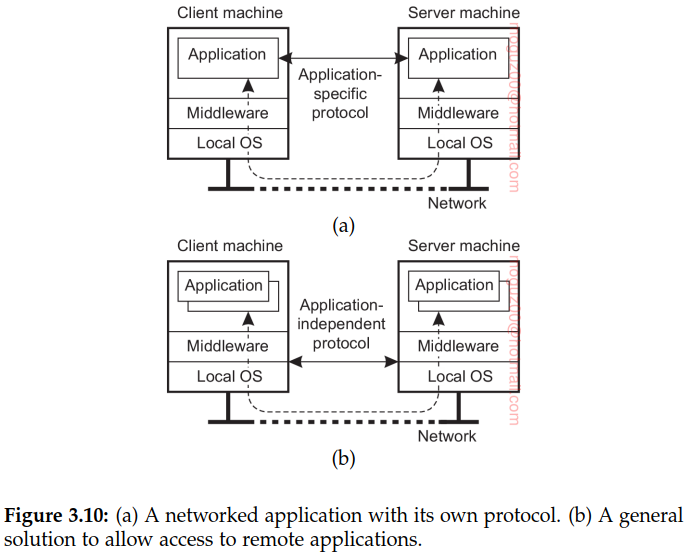
Client machines interact with remote servers. There are roughly two ways in which this interaction can be supported.
-
First, for each remote service the client machine will have a separate counterpart that can contact the service over the network. A typical example is a calendar running on a user’s smartphone that needs to synchronize with a remote, possibly shared calendar. In this case, an application-level protocol will handle the synchronization
-
Provide direct access to remote services by offering only a convenient user interface. Effectively, this means that the client machine is used only as a terminal with no need for local storage, leading to an application-neutral solution. In the case of networked user interfaces, everything is processed and stored at the server. This thin-client approach has received much attention with the increase of Internet connectivity and the use of mobile devices.
Thin-client network computing
As an alternative to using X, researchers and practitioners have also sought to let an application completely control the remote display, that is, up the pixel level. Changes in the bitmap are then sent over the network to the display, where they are immediately transferred to the local frame buffer. A well-known example of this approach is Virtual Network Computing (VNC)
Client-side software for distribution transparency
Client software comprises more than just user interfaces. In many cases, parts of the processing and data level in a client-server application are executed on the client side as well. A special class is formed by embedded client software, such as for automatic teller machines (ATMs), cash registers, barcode readers, TV set-top boxes, etc.
Access transparency is generally handled through the generation of a client stub from an interface definition of what the server has to offer. The stub provides the same interface as the one available at the server, but hides the possible differences in machine architectures, as well as the actual communication. The client stub transforms local calls to messages that are sent to the server, and vice versa transforms messages from the server to return values as one would expect when calling an ordinary procedure.
3.4 Servers
General design issues
A server is a process implementing a specific service on behalf of a collection of clients. It waits for an incoming request from a client and subsequently ensures that the request is taken care of, after which it waits for the next incoming request.
Concurrent versus iterative servers
Iterative server, the server itself handles the request and, if necessary, returns a response to the requesting client.
Concurrent server does not handle the request itself, but passes it to a separate thread or another process, after which it immediately waits for the next incoming request. A multithreaded server is an example of a concurrent server. An alternative implementation of a concurrent server is to fork a new process for each new incoming request. This approach is followed in many Unix systems. The thread or process that handles the request is responsible for returning a response to the requesting client.
Contacting a server: end points
Clients connect to server using end point and a port. FTP uses TCP port 21, HTTP server listens TCP port 80. These well known ports are defined in Internet Assigned Numbers Authority (IANA).
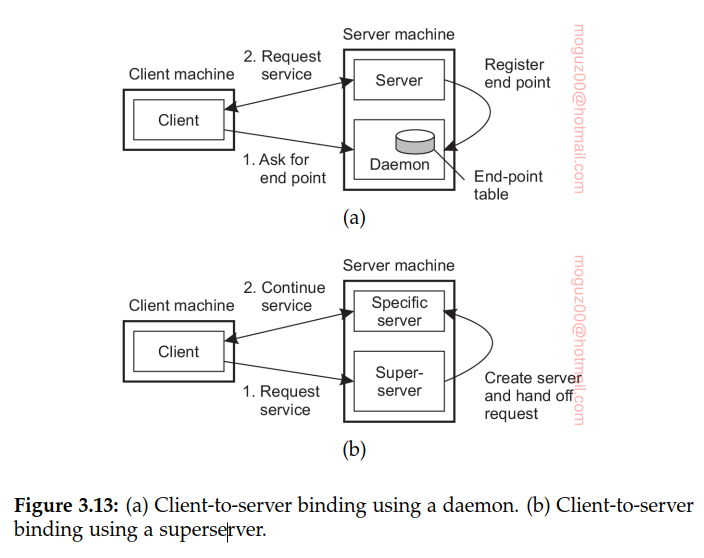
Interrupting a server
-
User to abruptly exit the client application (which will automatically break the connection to the server), immediately restart it, and pretend nothing happened.
-
Develop the client and server such that it is possible to send out-of-band data that is to be processed by the server before any other data from that client. Server listen to a separate control end point to which the client sends out-of-band data, while at the same time listening (with a lower priority) to the end point through which the normal data passes.
-
Send out-of-band data across the same connection through which the client is sending the original request.
Stateless versus stateful servers
Stateless server does not keep information on the state of its clients, and can change its own state without having to inform any client. Web server, for example, is stateless. It merely responds to incoming HTTP requests. Server maintains what is known as soft state. In this case, the server promises to maintain state on behalf of the client, but only for a limited time.
Stateful server generally maintains persistent information on its clients. File server that allows a client to keep a local copy of a file, even for performing update operations. If the server crashes, it has to recover its table of (client, file) entries, or otherwise it cannot guarantee that it has processed the most recent updates on a file.
Client send along additional information on its previous accesses. In the case of the Web, this information is often transparently stored by the client’s browser in what is called a cookie, which is a small piece of data.
Object servers
Difference between general object server and other (more traditional) servers is that an object server by itself does not provide a specific service. Specific services are implemented by the objects that reside in the server. Essentially, the server provides only the means to invoke local objects, based on requests from remote clients.
An object server thus acts as a place where objects live. An object consists of two parts: data representing its state and the code for executing its methods. Whether or not these parts are separated, or whether method implementations are shared by multiple objects, depends on the object server.
Transient object: an object that exists only as long as its server exists, but possibly for a shorter period of time. An in-memory, read-only copy of a file could typically be implemented as a transient object
The stub, also called a skeleton, is normally generated from the interface definitions of the object, unmarshals the request and invokes the appropriate method.
A servant is the general term for a piece of code that forms the implementation of an object.
Note 3.7 (Example: Enterprise Java Beans)
- Stateless session beans: once, does its work, after which it discards any information it needed to perform the service it offered to a client.
- Stateful session beans: maintains client-related state. The canonical example is a bean implementing an electronic shopping cart.
- Entity beans: long-lived persistent object. As such, an entity bean will generally be stored in a database, and likewise, will often also be part of transactions.
- Message-driven beans: used to program objects that should react to incoming messages (and likewise, be able to send messages). Message-driven beans cannot be invoked directly by a client, but rather fit into a publish-subscribe way of communication.
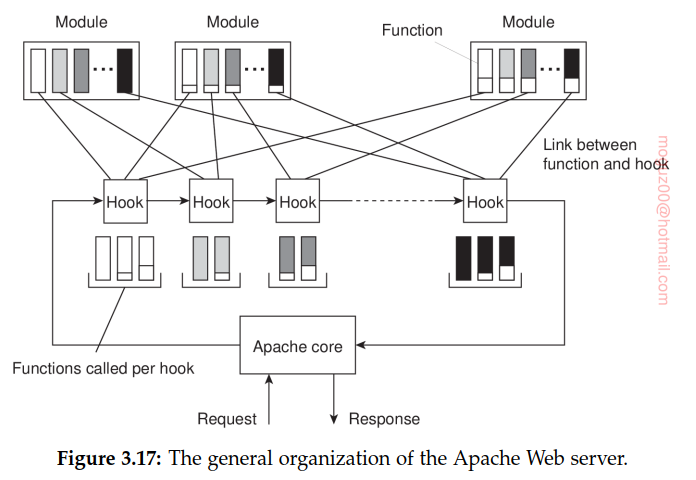
Example: The Apache Web server
Making the server platform independent is realized by essentially providing its own basic runtime environment, which is then subsequently implemented for different operating systems. Apache Portable Runtime (APR), file handling, networking, locking, threads.
HTTP is virtually always implemented on top of TCP, for which reason the core of Apache assumes that all incoming requests adhere to a TCP-based connection-oriented way of communication. Requests based on UDP cannot be handled without modifying the Apache core.
Fundamental to this Apache core organization is the concept of a hook, which is nothing but a placeholder for a specific group of function. The functions associated with a hook are all provided by separate modules.
Server clusters
Cluster computing as one of the many appearances of distributed systems.
Local-area clusters
Collection of machines connected through a network, where each machine runs one or more servers. Machines are connected through a local-area network, often offering high bandwidth and low latency.
General organization contains three tiers. First tier consists of a (logical) switch through which client requests are routed. Second tier servers dedicated to application processing. In cluster computing, these are typically servers running on high-performance hardware dedicated to delivering compute power. Third tier data-processing servers, notably file and database servers. Again, depending on the usage of the server cluster, these servers may be running on specialized machines, configured for high-speed disk access and having large server-side data caches.
This is not a strict design, the case that each machine is equipped with its own local storage, often integrating application and data processing in a single server leading to a two-tiered architecture is also possible.
Request dispatching consisting of the switch, also known as the front end. Hide the fact that there are multiple servers. This access transparency is invariably offered by means of a single access point, in turn implemented through some kind of hardware switch such as a dedicated machine. Transport-layer switches, the switch accepts incoming TCP connection requests, and hands off such connections to one of the servers. Two ways how the switch can operate.
In the first case, the client sets up a TCP connection such that all requests and responses pass through the switch. The switch, in turn, will set up a TCP connection with a selected server and pass client requests to that server, and also accept server responses (which it will pass on to the client). In effect, the switch sits in the middle of a TCP connection between the client and a selected server, rewriting the source and destination addresses when passing TCP segments. This approach is a form of network address translation (NAT)
Secondly, switch can actually hand off the connection to a selected server such that all responses are directly communicated to the client without passing through the server. The principle working of what is commonly known as TCP handoff.
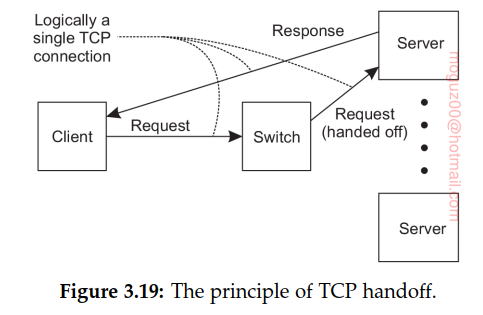
It can already be seen that the switch can play an important role in distributing the load among the various servers. The simplest load-balancing policy that the switch can follow is round robin: each time it picks the next server from its list to forward a request to. This may actually slow down the switch.
Transport-level switches, decisions on where to forward an incoming request is based on transport-level information only. One step further is to have the switch actually inspect the payload of the incoming request. This content-aware request distribution can be applied only if it is known what that payload looks like.
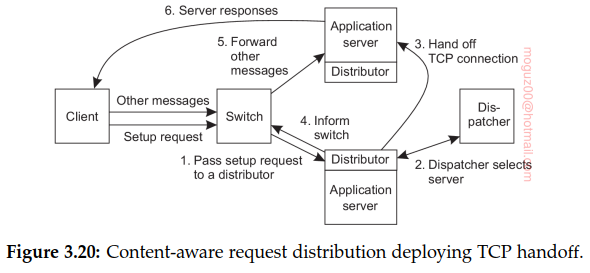
Wide-area clusters
Deal with multiple administrative organizations such as ISPs (Internet Service Providers). Distributed systems is to provide locality: offering data and services that are close to clients. Streaming media: the closer a video server is located to a client, the easier it becomes to provide high-quality streams.
Note that if wide-area locality is not critical, it may suffice, or even be better, to place virtual machines in a single data center, so that interprocess communication can benefit from low-latency local networks. The price to pay may be higher latencies between clients and the service running in a remote data center.
Request dispatching server should handle the client’s request is an issue of redirection policy.
Once a server has been selected, the dispatcher will have to inform the client. Several redirection mechanisms are possible. A popular one is when the dispatcher is actually a DNS name server. Internet or Web-based services are often looked up in the Domain Name System (DNS). A client provides a domain name such as service.organization.org to a local DNS server, which eventually returns an IP address of the associated service, possibly after having contacted other DNS servers. When sending its request to look up a name, a client also sends its own IP address (DNS requests are sent as UDP packets). In other words, the DNS server will also know the client’s IP address which it can then subsequently use to select the best server for that client, and returning a close-by IP address.
Unfortunately, this scheme is not perfect for two reasons. Not the client’s IP address, but that of the local DNS server is used to identify the location of the client. There may be a huge additional communication cost, as the local DNS server is often not that local. DNS server that is deciding on which IP address to return, may be fooled by the fact that the requester is yet another DNS server acting as an intermediate between the original client and the deciding DNS server. In those case, locality awareness has been completely lost.
Case study: PlanetLab
Collaborative distributed system in which different organizations each donate one or more computers, adding up to a total of hundreds of nodes. Together, these computers form a 1-tier server cluster, where access, processing, and storage can all take place on each node individually.
General Organization
Virtual machine monitor (VMM) an enhanced Linux operating system. The enhancements mainly comprise adjustments for supporting the second component, namely (Linux)Vservers, separate environment in which a group of processes run. The Linux VMM ensures that Vservers are separated: processes in different Vservers are executed concurrently and independently.
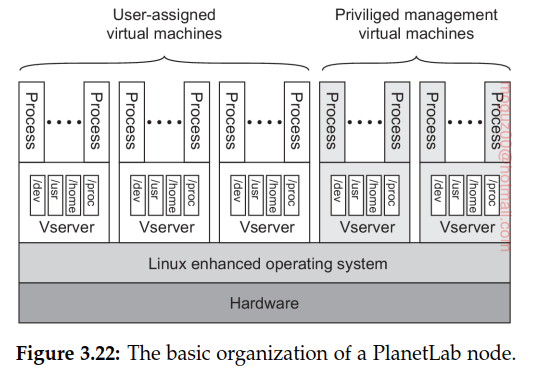
Central to managing PlanetLab resources is the node manager. Each node has such a manager, implemented by means of a separate Vserver, whose only task is to create other Vservers on the node it manages and to control resource allocation. To create a new slice, each node will also run a slice creation service (SCS), which, in turn, can contact the node manager requesting it to create a Vserver and to allocate resources.
Vservers
Container-based approach. primary task of a Vserver is therefore to merely support a group of processes and keep that group isolated from processes running under the jurisdiction(yetki alanı) of another Vserver. The main difference with traditional virtual machines is that they rely on a single, shared operating-system kernel. This also means that resource management is mostly done only by the underlying operating system and not by any of the Vservers.
An important advantage of the container-based approach toward virtualization in comparison to running separate guest operating systems, is that resource allocation can generally be much simpler. In particular, it is possible to overbook resources by allowing for dynamic resource allocation, just as is done with allocating resources to normal processes.
3.5 Code migration
Reasons for migrating code
Process migration in which an entire process was moved from one node to another. Overall system performance can be improved if processes are moved from heavily loaded to lightly loaded machines. Load is often expressed in terms of the CPU queue length or CPU utilization.
The important advantage of this model of dynamically downloading client-side software is that clients need not have all the software preinstalled to talk to servers. Instead, the software can be moved in as necessary, and likewise, discarded when no longer needed. Another advantage is that as long as interfaces are standardized, we can change the client-server protocol and its implementation as often as we like. Changes will not affect existing client applications that rely on the server.
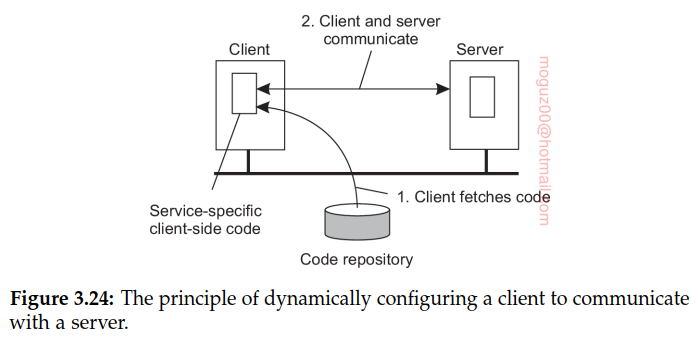
Note 3.10 (More information: Moving away from thin-client computing?)
By dynamically migrating client-side software, yet keeping the management of that software entirely at the server side (or rather, at its owner), having “richer” client-side software has become practically feasible.
Migration in heterogeneous systems
Simple solution to alleviate many of the problems of porting Pascal to different machines was to generate machine-independent intermediate code for an abstract virtual machine. All such solutions have in common that they rely on a (process) virtual machine that either directly interprets source code (as in the case of scripting languages), or otherwise interprets intermediate code generated by a compiler (as in Java).
Migration involves two major problems: migrating the entire memory image and migrating bindings to local resources:
- Pushing memory pages to the new machine and resending the ones that are later modified during the migration process.
- Stopping the current virtual machine; migrate memory, and start the new virtual machine. - unacceptable downtime
- Letting the new virtual machine pull in new pages as needed, that is, let processes start on the new virtual machine immediately and copy memory pages on demand.
3.6 Summary
Processes play a fundamental role in distributed systems as they form a basis for communication between different machines. An important issue is how processes are internally organized and, in particular, whether or not they support multiple threads of control. Threads in distributed systems are particularly useful to continue using the CPU when a blocking I/O operation is performed. In this way, it becomes possible to build highly-efficient servers that run multiple threads in parallel, of which several may be blocking to wait until disk I/O or network communication completes. In general, threads are preferred over the use of processes when performance is at stake.
Virtualization has since long been an important field in computer science, but in the advent of cloud computing has regained tremendous attention. Popular virtualization schemes allow users to run a suite of applications on top of their favorite operating system and configure complete virtual distributed systems in the cloud. Impressively enough, performance remains close to running applications on the host operating system, unless that system is shared with other virtual machines. The flexible application of virtual machines has led to different types of services for cloud computing, including infrastructures, platforms, and software — all running in virtual environments.
Organizing a distributed application in terms of clients and servers has proven to be useful. Client processes generally implement user interfaces, which may range from very simple displays to advanced interfaces that can handle compound documents. Client software is furthermore aimed at achieving distribution transparency by hiding details concerning the communication with servers, where those servers are currently located, and whether or not servers are replicated. In addition, client software is partly responsible for hiding failures and recovery from failures.
Servers are often more intricate than clients, but are nevertheless subject to only a relatively few design issues. For example, servers can either be iterative or concurrent, implement one or more services, and can be stateless or stateful. Other design issues deal with addressing services and mechanisms to interrupt a server after a service request has been issued and is possibly already being processed.
Special attention needs to be paid when organizing servers into a cluster. A common objective is to hide the internals of a cluster from the outside world. This means that the organization of the cluster should be shielded from applications. To this end, most clusters use a single entry point that can hand off messages to servers in the cluster. A challenging problem is to transparently replace this single entry point by a fully distributed solution.
Advanced object servers have been developed for hosting remote objects. An object server provides many services to basic objects, including facilities for storing objects, or to ensure serialization of incoming requests. Another important role is providing the illusion to the outside world that a collection of data and procedures operating on that data correspond to the concept of an object. This role is implemented by means of object adapters. Object-based systems have come to a point where we can build entire frameworks that can be extended for supporting specific applications. Java has proven to provide a powerful means for setting up more generic services, exemplified by the highly popular Enterprise Java Beans concept and its implementation.
An exemplary server for Web-based systems is the one from Apache. Again, the Apache server can be seen as a general solution for handling a myriad of HTTP-based queries. By offering the right hooks, we essentially obtain a flexibly configurable Web server. Apache has served as an example not only for traditional Web sites, but also for setting up clusters of collaborative Web servers, even across wide-area networks.
An important topic for distributed systems is the migration of code between different machines. Two important reasons to support code migration are increasing performance and flexibility. When communication is expensive, we can sometimes reduce communication by shipping computations from the server to the client, and let the client do as much local processing as possible. Flexibility is increased if a client can dynamically download software needed to communicate with a specific server. The downloaded software can be specifically targeted to that server, without forcing the client to have it preinstalled.
Code migration brings along problems related to usage of local resources for which it is required that either resources are migrated as well, new bindings to local resources at the target machine are established, or for which systemwide network references are used. Another problem is that code migration requires that we take heterogeneity into account. Current practice indicates that the best solution to handle heterogeneity is to use virtual machines. These can take either the form of process virtual machines as in the case of, for example, Java, or through using virtual machine monitors that effectively allow the migration of a collection of processes along with their underlying operating system.
Chapter 4 Communication
4.1 Foundations
Network communication protocols
Layered Protocols
Due to the absence of shared memory, all communication in distributed systems is based on sending and receiving (low level) messages.
The OSI reference model
International Standards Organization (ISO): clearly identifies the various levels involved, gives them standard names, and points out which level should do which job. Open Systems Interconnection Reference Model usually abbreviated as ISO OSI or sometimes just the OSI model. Communication protocols, To allow a group of computers to communicate over a network, they must all agree on the protocols to be used. A protocol is said to provide a communication service. There are two types of such services. In the case of a connection-oriented service, before exchanging data the sender and receiver first explicitly establish a connection, and possibly negotiate specific parameters of the protocol they will use. When they are done, they release (terminate) the connection. The telephone is a typical connection-oriented communication service. With connectionless services, no setup in advance is needed. The sender just transmits the first message when it is ready. Dropping a letter in a mailbox is an example of making use of connectionless communication service. With computers, both connection-oriented and connectionless communication are common.
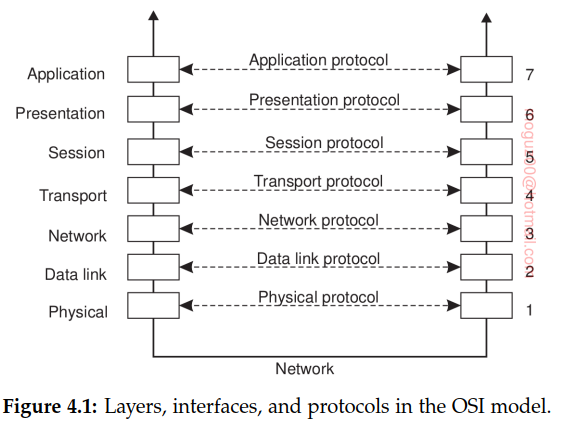
Each layer provides an interface to the one above it. The interface consists of a set of operations that together define the service the layer is prepared to offer. The seven OSI layers are:
- Physical layer Deals with standardizing how two computers are connected and how 0s and 1s are represented.
- Data link layer Provides the means to detect and possibly correct transmission errors, as well as protocols to keep a sender and receiver in the same pace.
- Network layer Contains the protocols for routing a message through a computer network, as well as protocols for handling congestion.
- Transport layer Mainly contains protocols for directly supporting applications, such as those that establish reliable communication, or support real-time streaming of data.
- Session layer Provides support for sessions between applications.
- Presentation layer Prescribes how data is represented in a way that is independent of the hosts on which communicating applications are running.
- Application layer Essentially, everything else: e-mail protocols, Web access protocols, file-transfer protocols, and so on.
When process P wants to communicate with some remote process Q, it builds a message and passes that message to the application layer as offered to it by means of an interface. This interface will typically appear in the form of a library procedure. The application layer software then adds a header to the front of the message and passes the resulting message across the layer 6/7 interface to the presentation layer. The presentation layer, in turn, adds its own header and passes the result down to the session layer, and so on. Some layers add not only a header to the front, but also a trailer to the end. When it hits the bottom, the physical layer actually transmits the message by putting it onto the physical transmission medium.
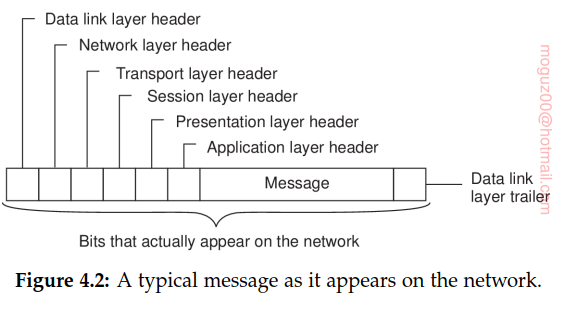
It is important to distinguish a reference model from its actual protocols. As said, the OSI protocols were never popular, in contrast to protocols developed for the Internet, such as TCP and IP.
Physical layer sends 0 and 1s, electrical, optical, mechanical and signaling interfaces. Group bits into frames. Datalink layer, adds checksum to frames. Finding best path is called routing, and is essentially the primary task of the network layer. Transport layer, makes sure application layer messages are guaranteed to be sent. Reliable transport, The Internet transport protocol is called TCP (Transmission Control Protocol). The combination TCP/IP is now used as a de facto standard for network communication. The Internet protocol suite also supports a connectionless transport protocol called UDP (Universal Datagram Protocol). To support real-time data transfer, the Real-time Transport Protocol (RTP). The session layer is essentially an enhanced version of the transport layer. It provides dialog control, to keep track of which party is currently talking, and it provides synchronization facilities. Unlike the lower layers, which are concerned with getting the bits from the sender to the receiver reliably and efficiently, the presentation layer is concerned with the meaning of the bits. In the presentation layer it is possible to define records containing fields like these and then have the sender notify the receiver that a message contains a particular record in a certain format. The OSI application layer was originally intended to contain a collection of standard network applications such as those for electronic mail, file transfer, and terminal emulation.
Middleware protocols
The Domain Name System (DNS) is a distributed service that is used to look up a network address associated with a name, such as the address of a so-called domain name like www.distributed-systems.net. DNS is offering a general-purpose, application-independent service. Arguably, it forms part of the middleware. Authentication protocols are not closely tied to any specific application, but instead, can be integrated into a middleware system as a general service.
Remote procedure call, a process is offered a facility to locally call a procedure that is effectively implemented on a remote machine.
Types of Communication
With persistent communication, a message that has been submitted for transmission is stored by the communication middleware as long as it takes to deliver it to the receiver. Transient communication, a message is stored by the communication system only as long as the sending and receiving application are executing.
The characteristic feature of asynchronous communication is that a sender continues immediately after it has submitted its message for transmission. This means that the message is (temporarily) stored immediately by the middleware upon submission. With synchronous communication, the sender is blocked until its request is known to be accepted.
4.2 Remote procedure call
Call procedures located on other machines. A server stub is the server-side equivalent of a client stub: it is a piece of code that transforms requests coming in over the network into local procedure calls.
Parameter passing
The Intel format is called little endian and the (older) ARM format is called big endian. Byte ordering is also important for networking:also here we can witness that machines may use a different ordering when transmitting (and thus receiving) bits and bytes. However, big endian is what is normally used for transferring bytes across a network.
To simplify matters, interfaces are often specified by means of an Interface Definition Language(IDL). An interface specified in such an IDL is then subsequently compiled into a client stub and a server stub, along with the appropriate compile-time or run-time interfaces.
The Message-Passing Interface (MPI)
4.5 Summary
Having powerful and flexible facilities for communication between processes is essential for any distributed system. In traditional network applications, communication is often based on the low-level message-passing primitives offered by the transport layer. An important issue in middleware systems is to offer a higher level of abstraction that will make it easier to express communication between processes than the support offered by the interface to the transport layer.
One of the most widely used abstractions is the Remote Procedure Call (RPC). The essence of an RPC is that a service is implemented by means of a procedure, of which the body is executed at a server. The client is offered only the signature of the procedure, that is, the procedure’s name along with its parameters. When the client calls the procedure, the client-side implementation, called a stub, takes care of wrapping the parameter values into a message and sending that to the server. The latter calls the actual procedure and returns the results, again in a message. The client’s stub extracts the result values from the return message and passes it back to the calling client application.
RPCs offer synchronous communication facilities, by which a client is blocked until the server has sent a reply. Although variations of either mechanism exist by which this strict synchronous model is relaxed, it turns out that general-purpose, high-level message-oriented models are often more convenient.
In message-oriented models, the issues are whether or not communication is persistent, and whether or not communication is synchronous. The essence of persistent communication is that a message that is submitted for transmission, is stored by the communication system as long as it takes to deliver it. In other words, neither the sender nor the receiver needs to be up and running for message transmission to take place. In transient communication, no storage facilities are offered, so that the receiver must be prepared to accept the message when it is sent.
In asynchronous communication, the sender is allowed to continue immediately after the message has been submitted for transmission, possibly before it has even been sent. In synchronous communication, the sender is blocked at least until a message has been received. Alternatively, the sender may be blocked until message delivery has taken place or even until the receiver has responded as with RPCs.
Message-oriented middleware models generally offer persistent asynchronous communication, and are used where RPCs are not appropriate. They are often used to assist the integration of (widely dispersed) collections of databases into large-scale information systems.
Finally, an important class of communication protocols in distributed systems is multicasting. The basic idea is to disseminate information from one sender to multiple receivers. We have discussed two different approaches. First, multicasting can be achieved by setting up a tree from the sender to the receivers. Considering that it is now well understood how nodes can self-organize into peer-to-peer system, solutions have also appeared to dynamically set up trees in a decentralized fashion. Second, flooding messages across the network is extremely robust, yet requires special attention if we want to avoid severe waste of resources as nodes may see messages multiple times. Probabilistic flooding by which a node forwards a message with a certain probability often proves to combine simplicity and efficiency, while being highly effective.
Another important class of dissemination solutions deploys epidemic protocols. These protocols have proven to be very simple and extremely robust. Apart from merely spreading messages, epidemic protocols can also be efficiently deployed for aggregating information across a large distributed system.
Chapter 5 Naming
5.1 Names, identifiers, and addresses
An access point is yet another, but special, kind of entity in a distributed system. The name of an access point is called an address. The address of an access point of an entity is also simply called an address of that entity.
A true identifier is a name that has the following properties:
- An identifier refers to at most one entity.
- Each entity is referred to by at most one identifier.
- An identifier always refers to the same entity (i.e., it is never reused).
human-friendly name is generally represented as a character string.
naming system maintains a name-to-address binding which in its simplest form is just a table of (name, address) pairs.
5.2 Flat naming
two simple solutions for locating an entity: broadcasting and forwarding pointers. Both solutions are mainly applicable only to local-area networks.
Broadcasting
This principle is used in the Internet Address Resolution Protocol (ARP) to find the data-link address of a machine when given only an IP address
Forwarding pointers
when an entity moves from A to B, it leaves behind in A a reference to its new location at B.
Home-based approaches
keeps track of the current location of an entity
Distributed hash tables
General mechanism
Chord system being a typical representative.
FTp[i] = succ(p + 2(to)(i−1))
Chord figure and logic
5.3 Structured naming
Flat names are good for machines, but are generally not very convenient for humans to use. As an alternative, naming systems generally support structured names that are composed from simple, human-readable names. Not only file naming, but also host naming on the Internet follows this approach.
The naming graph shown in Figure 5.11 has one node, namely n0, which has only outgoing and no incoming edges. Such a node is called the root (node) of the naming graph. Although it is possible for a naming graph to have several root nodes, for simplicity, many naming systems have only one. Each path in a naming graph can be referred to by the sequence of labels corresponding to the edges in that path, such as N:[label1, label2, …, labeln], where N refers to the first node in the path. Such a sequence is called a path name. If the first node in a path name is the root of the naming graph, it is called an absolute path name. Otherwise, it is called a relative path name.
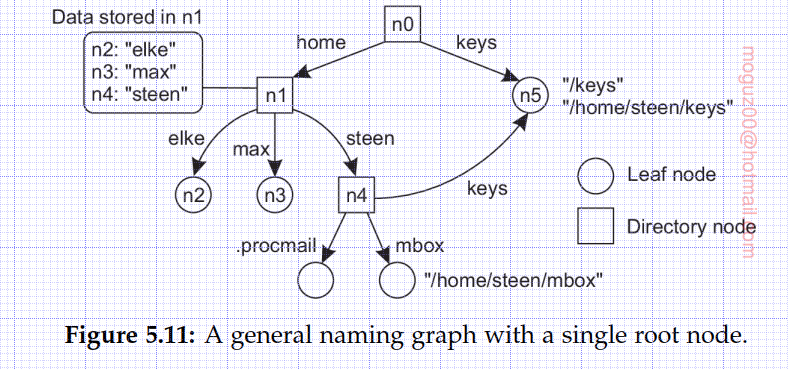
Implementing the Unix naming graph
• An omission failure occurs when a component fails to take an action that it should have taken. • A commission failure occurs when a component takes an action that it should not have taken
An overlay network is a computer network that is built on top of another network. Wikipedia
Power usage effectiveness (PUE)
Is a ratio that describes how efficiently a computer data center uses energy; specifically, how much energy is used by the computing equipment (in contrast to cooling and other overhead). PUE was originally developed by a consortium called The Green Grid. [2]

PUE = Total in DC / Total by server
PUE = (Pservers + Pcrac) / Pserver => if PUD = 1, it is perfect
6 digit
References
[1] Andrew S. Tanenbaum and Maarten van Steen. 2006. Distributed Systems: Principles and Paradigms (2nd Edition). Prentice-Hall, Inc., Upper Saddle River, NJ, USA.
[2] https://en.wikipedia.org/wiki/Power_usage_effectiveness