
Deep Learning Notes 5 Neural Networks Part 2
In this post, I’ll coptinue to share my notes in CS231N course that is thought at Stanford University.
Activation Functions Activation functions are just nodes that are added to the output of any neural network. Aka Transfer Function.
Why we use activation functions in Neural Networks? It is used to determine the output of NN to Yes or No. These functions map the results into values to 0 to 1 or 1 to -1.
The Activation Functions can be basically divided into 2 types- Linear Activation Function and Non-linear Activation Functions. Today mostly non-linear activation functions are used.
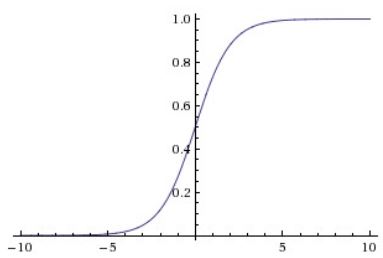
Sigmoid:
- Most used one in past.
- Squashes numbers in range of [0, 1]
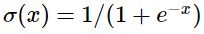
Cons:
- Vanishing gradient at saturated rejimes, it basically kills the gradients. It works on active region of sigmoid.
- Outputs are not zero centered. Preprocessed data must be zero centered. If all the inputs to a neuron is positive, then gradients will always be negative or positive. We get a zigzag path through the point.
- exp() function in sigmoid is expensive to compute
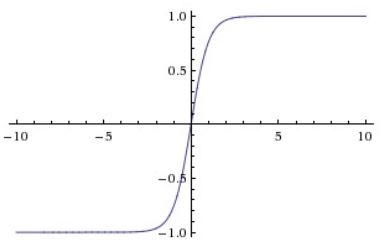
Tanh: Yann LeCun founded at 1991. It basically zero centered sigmoid. Squashes numbers between [-1, 1]. But, it still kills the gradients at saturated regions. Tanh is preferred over sigmoid.
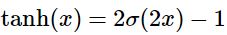
ReLU Krizhevsky founded at 2012 that Rectified Linear Unit converges 6x times faster than sigmoid and tanh. It does not saturates and it is computationally efficient. It does not saturate in positive region. No vanishing gradient problem. This is default recommendation for now. ReLU is like a gradient gate. If value is bigger than zero it passes as it is. If not it kills it.
- Cons Not zero centered output Annoying if < 0

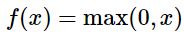
Dead ReLU problem: Initialize neurons with positive biases (0.01)
Leaky ReLU Same as the ReLU accept there is no dead neuron problem. A better version of ReLU. The negative values of relu is all 0, however in leaky relu, the function value is a constant times x. The constant is generally 0.01.
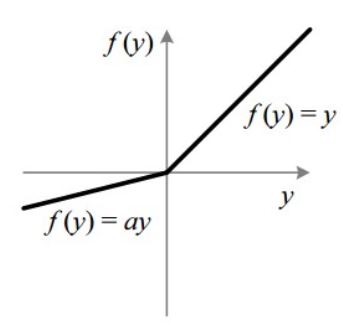

Parametric Rectifier (PReLU) In parametric ReLU, the constant can be parametric. And that parameter can be learned during backpropogation.
Exponential Linear Unit (ELU)
- Get all power of relu
- Get rid of the non centered feature of ReLU
-
Does not die
- Computation requires exp()
Maxout Neuron
- Does not have basic form of dot product -> non linearity
- Generalizes ReLU and Leaky ReLU
-
Linear Regime! Does not saturate! Does not die!
- Doubles the # of parameters/neurons
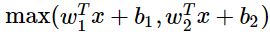
References
[1] [2] https://www.youtube.com/watch?v=gYpoJMlgyXA [3] https://towardsdatascience.com/activation-functions-neural-networks-1cbd9f8d91d6